ABSTRACT
Detecting and analyzing defects in components or systems is crucial for maintaining high-quality standards in modern manufacturing and quality control. Recently, imaging-based defect detection methods have gained popularity across various engineering fields, highlighting their growing importance. Additionally, the integration of Artificial Intelligence (AI) to improve accuracy and efficiency is rapidly advancing. This paper presents a system that uses imaging to detect holes in CV joint boots, as these holes significantly affect the overall performance and durability of the system. Moreover, it introduces a method for enhancing detection performance by applying AI techniques. Validation tests on actual CV joint boots confirmed that the proposed method improves detection performance.
-
KEYWORDS: CV joint boot, Image processing, Image sum, YOLO, U-Net, Hole detection
-
KEYWORDS: CV조인트 부트, 영상 처리, 영상 합산, 욜로, 유-넷, 홀 탐지
1. 서론
최근 영상 처리 기술의 급격한 발전은 제조업, 의료, 농업 등 다양한 산업에 혁신을 가져왔다. 이러한 기술의 응용 분야 중 결함 탐지는 영상 처리가 중요한 역할을 하는 핵심 영역으로 부각되고 있다. 결함 탐지란 객체, 재료 또는 시스템에서 발생하는 이상 또는 불규칙성을 식별하고 분석하는 과정을 의미한다. 현대 제조업과 품질 관리에서 제품 및 재료의 결함을 감지하는 것은 높은 품질 기준을 유지하고 폐기물을 줄이는 데 필수적이다.
전통적인 결함 탐지 방법은 주로 수작업 검사에 의존하며, 기존의 수작업 검사 방식은 숙련된 작업자의 경험에 의존하는 경향이 있다. 이는 높은 비용, 낮은 일관성, 그리고 인간의 오류 가능성을 초래할 수 있다[
1]. 이러한 한계를 극복하기 위해 영상 처리를 활용한 자동 결함 탐지 기술이 주목받고 있다. 이와 같은 영상 처리를 활용한 결함 탐지 방법은 더욱 강력하고 확장 가능한 솔루션을 제공함으로써 제조업뿐 아니라 의료, 반도체, 건설 등 다양한 산업에서 활용되고 있다[
2]. 이러한 접근 방식은 품질 관리 프로세스를 개선할 뿐만 아니라 운영 비용과 다운 타임을 줄이는 데 기여한다.
영상처리를 활용한 결함 탐지 시스템은 일반적으로 이미지 획득, 전처리, 특징 추출, 결함 분류 등의 단계로 구성된다. 먼저, 고해상도 카메라 및 센서를 사용하여 결함 대상의 이미지를 획득한 후, 노이즈 제거 및 대비 향상과 같은 전처리 과정을 거쳐 분석의 정확도를 높인다[
3]. 다음으로, 경계 검출, 히스토그램 분석, 기하학적 특징 추출 등의 기법을 이용하여 결함 영역을 검출하고, 최종적으로 머신러닝(Machine Learning, ML), 딥러닝(Deep Learning, DL) 기반 알고리즘을 적용하여, 결함 여부를 판별한다[
4].
이미지 합산(Image Sum)을 전처리 과정에 활용하여 결함 탐지 정확도를 높인 연구 사례들도 존재한다. DM Tsai 등은 PCB(인쇄 회로 기판)의 결함을 탐지하기 위해 정상적인 PC B Template 이미지와 검사 대상인 PC B 이미지에 대해 Image Sum을 포함한 다양한 연산을 적용하여 특징을 추출하고, 결함 탐지 알고리즘에 적용하여 결함의 종류를 효과적으로 파악하였다[
5]. 또한, 반사율이 높은 금속 부품 표면에 대해 여러 각도에서 촬영한 이미지들을 합산하여 딥러닝 모델의 입력 이미지로 활용함으로써 결함 검출 정확도를 향상시킨 연구 사례도 보고된 바 있다[
6].
최근에는 인공지능(Artificial Intelligence, AI) 기술이 영상처리에 접목되면서 결함 탐지 시스템의 탐지 정확도와 신뢰도가 크게 향상되었다. 합성곱 신경망(Convolutional Neural Networks, CNN) 및 순환 신경망(Recurrent Neural Networks, RNN) 등의 딥러닝 모델은 기존의 전통적인 영상처리 기법보다 높은 성능을 보이며, 복잡한 패턴을 가진 결함도 효과적으로 탐지할 수 있다[
7]. 또한, 데이터 증강 및 전이 학습(Transfer Learning) 기법을 활용하여 소량의 학습 데이터로도 높은 성능을 유지할 수 있어 실무 적용성이 더욱 커지고 있다[
8].
본 논문에서는 이러한 선행 연구들을 토대로 영상 처리 기법을 활용하여 제조 과정에서 발생된 Constant Velocity (CV) 조인트 부트의 관통 홀 탐지법을 검토한다. 그리고 영상 처리 기법을 AI와 결합하여 그 성능을 제고하는 방법을 제시하고 그 효과를 비교 분석한다. 본 논문의 구성은 다음과 같다. 2장은 본 연구의 대상물인 CV 조인트 부트와 그 내부에 존재하는 관통 홀 탐지의 필요성을 설명한다. 3장에서는 관통 홀 탐지 시스템의 구성과 작동 기전을 설명한다. 4장에서는 부트 내에 존재하는 관통 홀을 탐지하기 위한 영상처리 방법과 성능 제고를 위한 인공지능 분석 기법을 소개하고, 테스트 제품에 대한 결과를 정확도와 속도 측면에서 비교한다. 5장에서는 결론을 제시하고 본 연구가 갖는 한계점 및 향후 연구에 대하여 기술한다.
2. CV 조인트 부트
2.1 CV 조인트의 개요
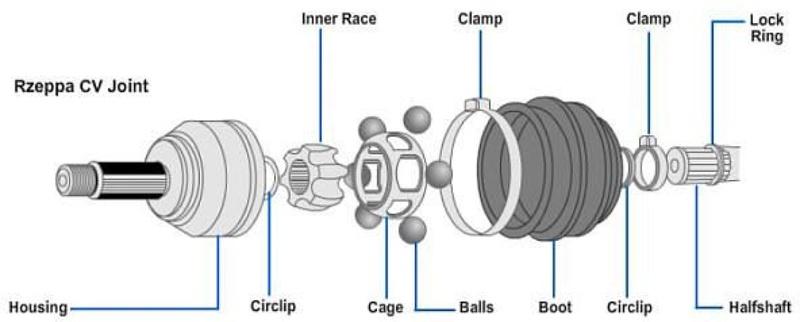
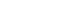
CV 조인트는 자동차 구동계의 중요한 부품으로 다양한 각도로 교차하는 두 축 사이에서 일정한 회전속도를 유지하면서 동력을 전달한다. 또한 코너링 및 요철 도로에서 서스펜션의 움직임을 허용하면서 일정한 속도로 회전 토크를 전달함으로 차량의 핸들링 성능과 승차감을 향상시키는 기계적인 조인트이다. CV 조인트의 내부 구조는
Fig. 1에 설명되어 있다. 그림에서 보는 바와 같이 조인트의 한 쪽 축에 전달된 토크는 Inner Race, Ball, Cage 및 Housing 등을 통해 조인트의 다른 쪽 축에 전달된다. 하우징은 외부 케이스로 내부 부품을 보호하며, 볼 베어링 또는 롤러는 축의 부드러운 회전을 가능하게 한다. 조인트의 작동 기전을 고려할 때, 구성 부품 사이의 마찰이 필연적이며 이를 저감하기 위하여 내부에는 윤활을 통해 조인트의 마모와 파손을 방지하는 고품질의 그리스가 도포된다. 그리스는 부트라고 알려진 CV 조인트의 커버 내부에 봉입되어 있으며 조인트를 감싸고 보호하여 변속기로부터 구동 바퀴로 토크가 원활하게 전달될 수 있게 한다. 부트가 파손되면 내부 그리스 유출 및 오염으로 인해 베어링이 손상되고 이에 따라 이상 소음과 진동이 발생된다.
Fig. 1Internal structure of the CV joint
2.2 CV 조인트 부트
이와 같은 부트는 일반적으로 내구성이 있는 합성고무 또는 열가소성 플라스틱 소재로 제조되며 먼지, 수분 및 각종 불순물로 인해 CV 조인트가 오염되는 것을 방지한다. 또한, 내부 부품 윤활용 그리스의 유출을 방지하기 위해 부트는 철제 클램프를 통해 조인트와 액슬 샤프트에 고정된다. 그리스가 유출되면 조인트에 이상 마모와 이에 따른 파손이 발생될 위험이 있으므로 제조 과정에서 부트에 발생된 관통 홀을 철저히 검출하고 해당 문제점이 있는 부트를 조인트 조립 공정에서 배제하는 것이 필수적이다. 또한, 생산 공정의 효율성을 고려하면 부트 제작의 마지막 공정 이후, 생산되는 모든 부트에 대해 신속하게 홀을 검출해야 할 필요가 있다. 이와 같은 검사를 위하여 부트의 내부에서 외부 방향으로 빛을 조사하고 부트 외부에서 누출되는 빛을 감지하여 홀을 탐지하는 시스템을 고안하였다.
3. 관통 홀 탐지 시스템
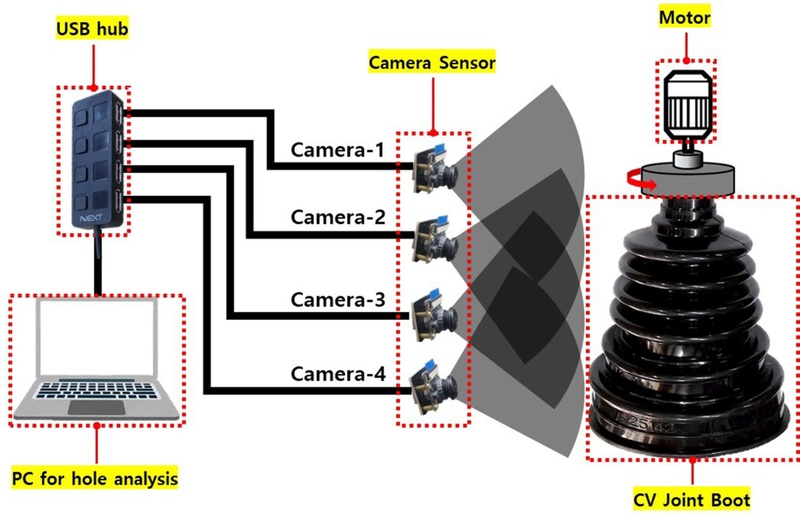
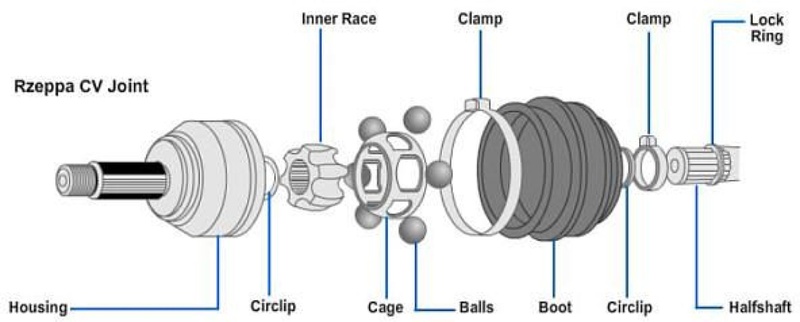
이 검사 시스템의 구성이 다음
Fig. 2에 설명되어 있다. 그림에서 보는 바와 같이 부트는 회전하는 고정대 상에 고정한 후 부트 내부에 설치된 LED 광원을 이용하여 외측으로 빛을 조사한다. 이 상태에서 부트를 회전시키면서 외부에 설치된 복수의 카메라(IMX415, 4K USB 카메라 모듈)를 통해 부트를 촬영한다.
Fig. 2 System for the detection of holes in the CV joint boot
부트에 관통 홀이 존재하는 경우 홀을 통해 조사된 빛이 누출되어 홀이 없는 부분과 다른 영상을 발생시킨다. 이렇게 촬영된 영상은 컴퓨터 저장장치에 수집된다. 수집된 영상을 다양한 방법으로 분석하여 내부에서 조사된 빛의 누출을 통해 부트에 존재하는 관통 홀을 탐지할 수 있다. 이 연구의 영상 분석에는 NVIDIA GeForce GTX 1650 with Max-Q Design 11.9GB의 GPU를 장착한 ASUS사의 ZenBook UX534FTC Laptop 컴퓨터를 사용하였다.
4. 관통 홀 탐지를 위한 영상처리 기법
카메라를 통해 동일한 부트의 이미지 데이터가 입력되어도 분석 기법에 따라 관통 홀 탐지 성능이 상이하게 나타나는 경우가 있다. 따라서, 높은 정확도를 가진 관통 홀 분석 기법은 적용하는 것이 필수적이다. 또한, 생산 라인에 적용하기 위해서는 검사 시간 최소화도 요구된다. 본 논문에서는 기존 방법인 ‘Image Sum (IS) Method’와 AI를 활용한 ‘U-Net Method’, ‘YOLO Method’를 비교, 검토하고 최적의 방법을 선정한다.
4.1 IS Method
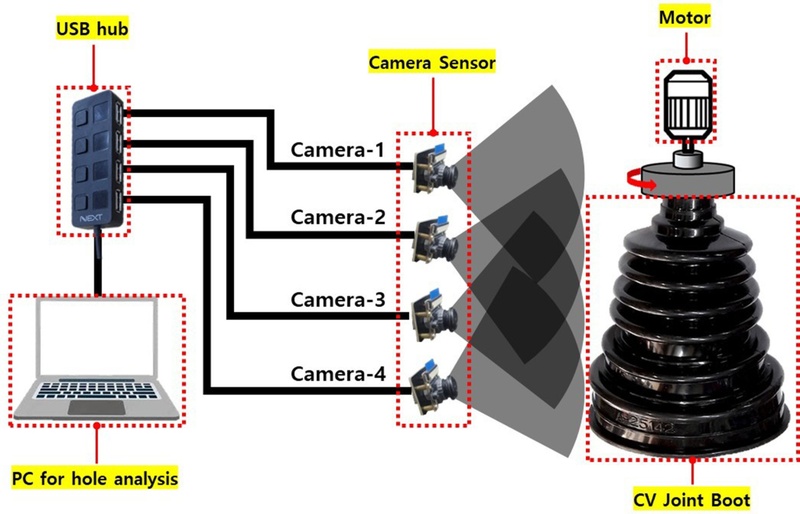
이 방법은 카메라 영상에 대한 단순한 연산을 통해 검사 대상물 내 홀 존재 여부만 파악하는 방법이다.
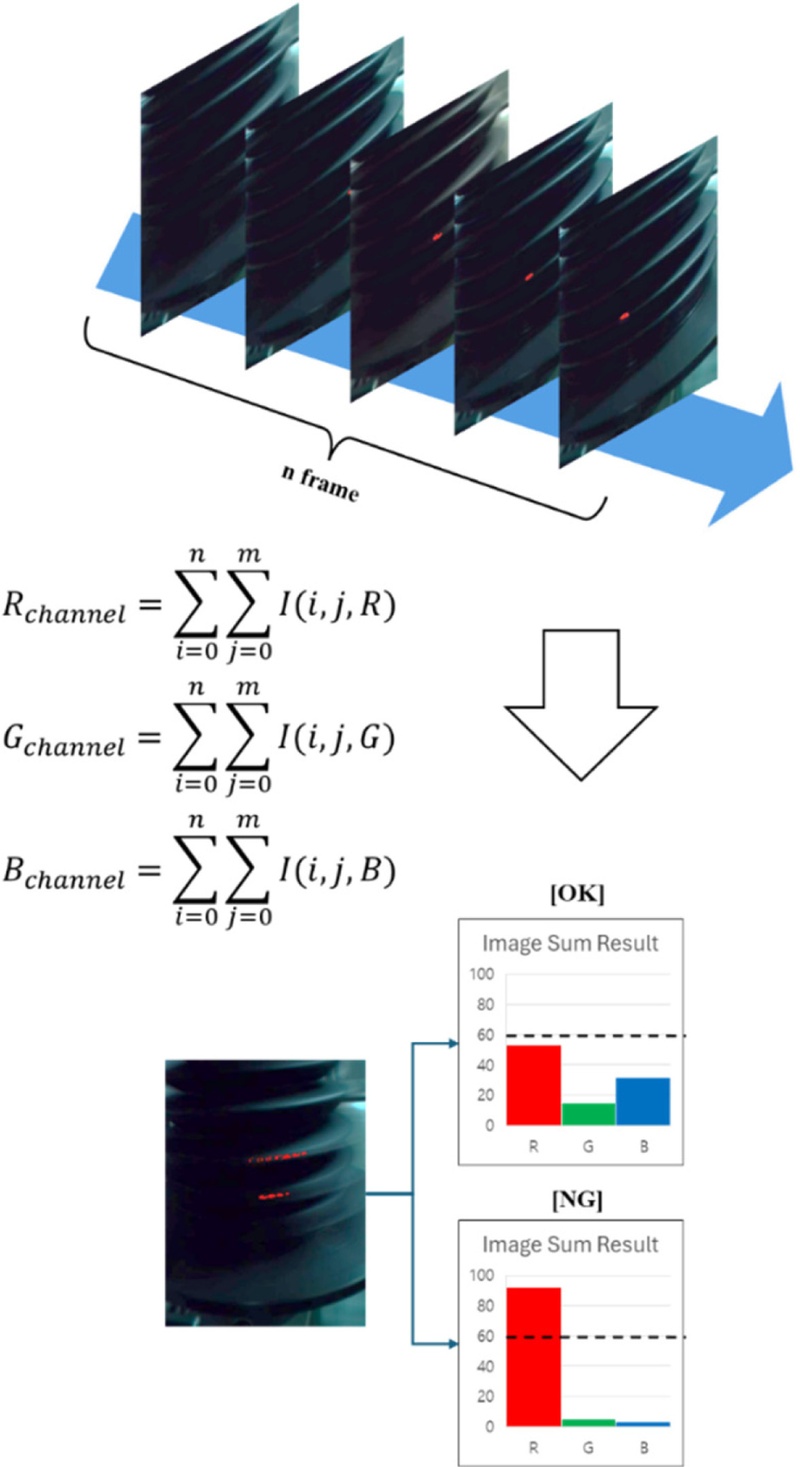
Fig. 3에 이 영상 처리 방법이 설명되어 있다.
Fig. 3Image processing in Image Sum method
그림에서 보는 바와 같이
Fig. 2의 검사 시스템을 이용하여 대상물이 1회전하는 동안 촬영된 영상의 모든 이미지의 RGB 값을 단순 합산하고, 영상 내의 부트 내 LED 램프와 동일한 색상이 설정된 Threshold 값 초과 여부를 통해 관통 홀 존재를 판정한다. 이 방식은 구현이 간단하고 홀 검출 환경이 일정하면 높은 정확도를 보일 정도로 효율적이지만, ① 최적 값 설정의 어려움, ② 환경 변화로 인한 코드 수정 필요, ③ 고정대와 샘플 사이의 빛 누출 또는 반사로 인한 결함 오판 가능성 등의 한계가 있다. 따라서, 해당 문제점들을 극복할 수 있는 검출 방법을 도출하기 위하여 관통 홀 판단 기준을 설정하기 쉬우면서 환경 변화에 강건하고 결함 오판 가능성이 낮은 AI 모델을 이용한 영상처리 기법을 검토한다.
앞에서 설명한 바와 같이 본 연구에서 ‘U-Net Method’와 ‘YOLO Method’ 두 AI 기반 방법에 대해서 검토한다. 이들 방법은 전체 이미지에 대해 픽셀 단위로 분류를 수행하므로 이미지 한 장 단위로 결함 검출이 가능하다. 상기 두 방법의 적용을 위해서는 홀이 포함된 이미지와 포함되지 않은 이미지를 Labeling한 데이터를 이용한 사전학습이 각각 필요하며, 이를 위한 데이터 세트 구축 과정은 다음과 같다.
- 1단계(Data Acquisition): Fig. 2 관통 홀 검출 시스템에서 관통홀이 1개 존재하는 학습용 CV 조인트 부트 샘플 1개를 대상으로 USB Hub로 연결된 4개의 카메라를 사용하여 수행됨. 4대의 카메라는 동시에 연결되어 있으며, Python의 OpenCV 라이브러리를 이용하여 4개의 각 카메라를 10초간 30fps 속도로 영상을 캡처하여 수집.
- 2단계(Labeling): Roboflow AI 플랫폼을 사용하여 U-Net 학습을 위한 Segmentation Labeling, YOLO 학습을 위한 Bounding Box Labeling을 수행.
AI 모델 학습에 사용된 이미지 데이터는 총 1,200장이며, 해상도는 240 × 320이다. 학습에 활용된 데이터에 대해 훈련 세트와 검증 세트 분할 비율 및 Label에 따른 비율은
Table 1에 제시되어 있다.
Table 1Composing training set and validation set
Table 1
|
Data set |
Label |
Quantity |
|
Training (80%) |
0 (Normal) |
808 |
|
1 (Defect) |
152 |
|
Validation (20%) |
0 (Normal) |
215 |
|
1 (Defect) |
25 |
(1) U-Net Method
이 방법 전체 과정은
Fig. 4에 설명되어 있다. 그림에서 나타난 바와 같이 U-Net은 Encoder, Decoder로 크게 두 부분으로 구성된다. Encoder는 Convolution Layer와 Pooling Layer로 이루어진 인코더 블록을 사용한다. 이를 통해 입력 이미지 특징을 추출하면서 점진적으로 해상도를 축소, 압축한다. 이 때, Convolution Layer에서 특징을 추출하기 위한 커널 크기를 3 × 3으로 설정하고 커널의 이동량인 Strides를 1로 설정했으며, 활성화 함수는 ‘relu’를 사용하고, Convolution Layer의 출력 크기를 일정하게 하기 위해 same padding을 적용했다. 각 Convolution Layer 이후에 학습 안정성을 높이기 위해 Batch Normalization(배치 정규화)을 수행한다. 이 때 2 × 2 커널과 Strides가 2인 MaxPooling 연산을 적용하여 특징 맵의 공간적 해상도를 절반으로 축소한다. 이러한 방식으로 16, 32, 64개의 필터 수를 단계적으로 증가시키며 총 3개의 인코더 블록을 구성하였다.
Fig. 4Image processing in U-Net method
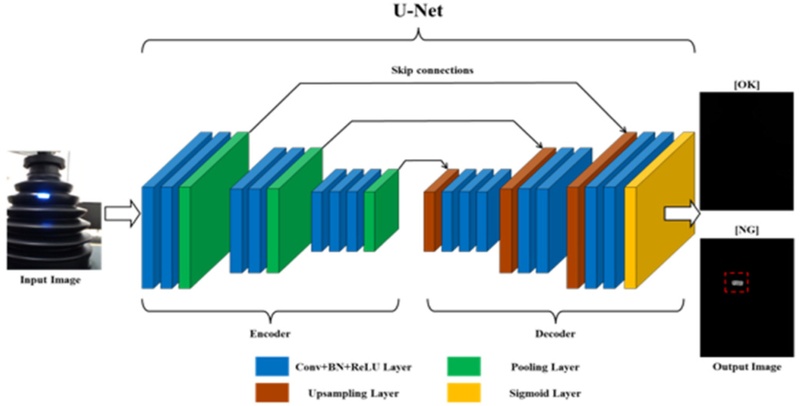
Decoder는 이렇게 압축된 특징 맵을 Upsampling Layer(Conv2DTranspose Layer)와 Convolution Layer로 이루어진 디코더 블록을 사용한다. 이를 통해 축소된 특징 맵을 원본 이미지 크기로 복원하여 관통 홀 검출 결과를 출력한다. 디코더 블록은 2 × 2 크기의 커널과 strides가 2인 Up-sampling(Conv2DTranspose)을 이용하여 축소된 특징 맵 크기를 두 배로 확대한다. 이 과정에서 Concatenate 연산으로 구현된 Skip Connection을 사용하여 Encoder에서 추출된 세부 정보를 Decoder에 전달함으로써 특징 정보의 손실을 최소화한다. 마지막 디코더 블록에서 생성된 특징 맵은 1 × 1 크기의 커널과 Strides가 1, 활성화 함수는 Sigmoid인 Conv2D를 통해 단일 채널의 관통홀의 확률 맵 형태로 출력된다. 본 논문의 디코더 블록는 인코더 블록과 대칭적으로 64, 32, 16개로 필터 수를 단계적으로 감소시키며 3개의 디코더 블록을 구성하였다.
사전학습에서 모델 최적화 방법으로 Adam Optimizer를 사용하였고, 이진 분류 문제에 적합한 binary_crossentropy를 손실 함수로 설정하였다. 또한, 전체 데이터를 학습시키는 횟수(Epoch)를 500으로 설정했으며, 각 학습 단계에서 동시에 처리하는 데이터 수(batch_size)를 256으로 설정하였다. 또한, 학습의 효율성을 높이고 과적합(Overfitting)을 방지하기 위해 조기 종료(EarlyStopping)를 적용하였다. 조기 종료는 검증 데이터 손실값(val_loss) 감소가 100회 연속 0.001 이하(patience = 100, min_delta = 0.001)인 경우 더 이상 의미 있는 학습이 이루어지지 않는다고 판단, 학습을 종료하는 방식으로 설정하였다.
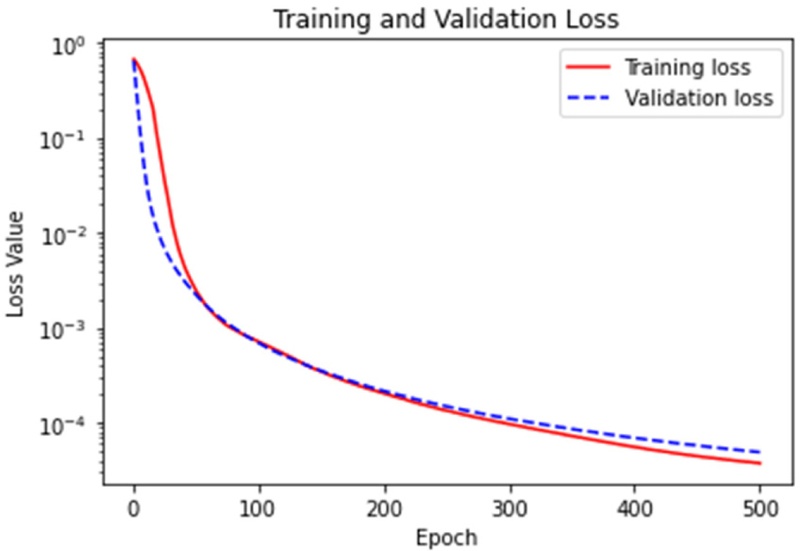
Table 1에 설명된 데이터 세트를 이용한 U-Net 학습 결과는
Fig. 5와 같다.
Fig. 5Loss of training and valid sets in U-Net model
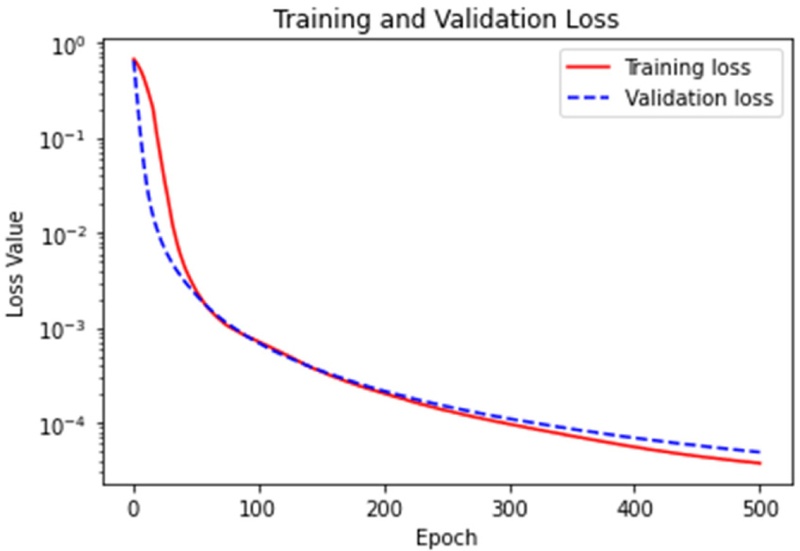
그림에서 보는 바와 같이 훈련 손실과 검증 손실 모두 지속적으로 감소하며, 훈련 손실이 약간 낮으나 검증 손실과 큰 차이가 없으므로 과적합이 거의 없음을 확인할 수 있다. 따라서, 그림과 같이 학습된 모델을 관통 홀 검출 모델로 활용했다.
이 방법을 적용한 결과가
Fig. 6에 설명되어 있다. 그림에서 보는 바와 같이 이미지 상에서 홀의 위치를 검출할 수 있음을 알 수 있다. 그러나 이미지의 좌측 코너에서 보는 바와 같이 빛을 유출한 부트와 고정대 사이의 틈새를 홀로 검출하는 오류를 발생시켰음을 알 수 있다.
Fig. 6Hole detection results using U-Net method

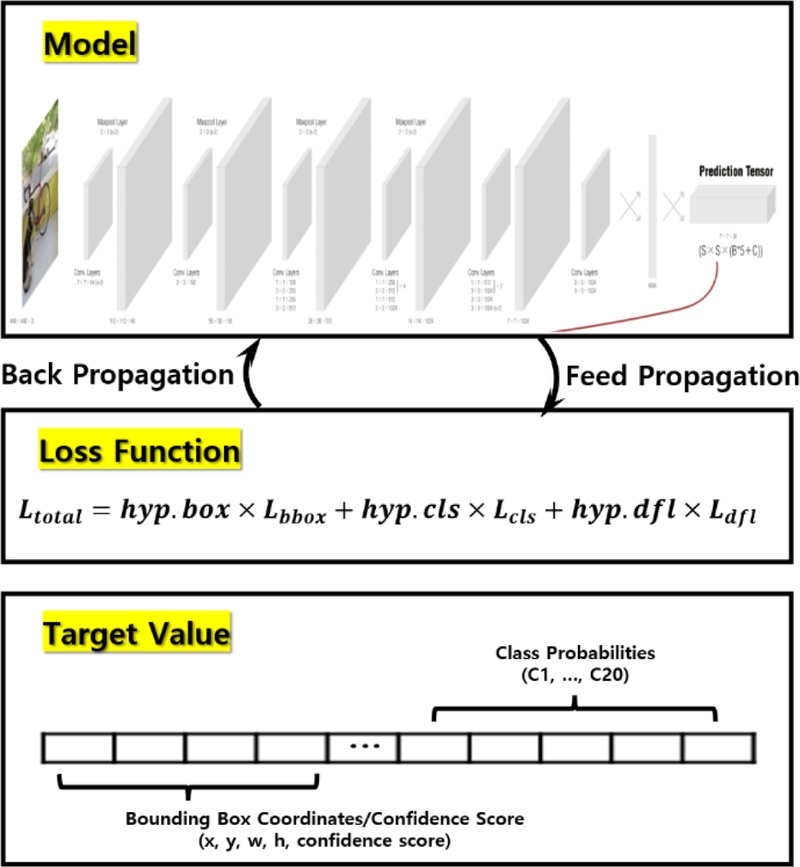
(2) YOLO Method
Fig. 7에서 알 수 있는 바와 같이 이 방법도 적용을 위한 사전학습이 필요하다. 본 연구에서는 Ultralytics에서 사전학습된 YOLOv8n 모델을 기반으로, 기존 구조와 가중치를 유지하면서 새로운 데이터셋에 맞춰 미세 조정(Fine-tuning)을 수행하였다. 사전학습의 파라미터는 U-Net과 동일하게 설정하였다. 기타 분석 파라미터는 기본값을 사용했으며 YOLO 학습 결과는
Fig. 8과 같다.
Fig. 7YOLO-based training process for hole detection
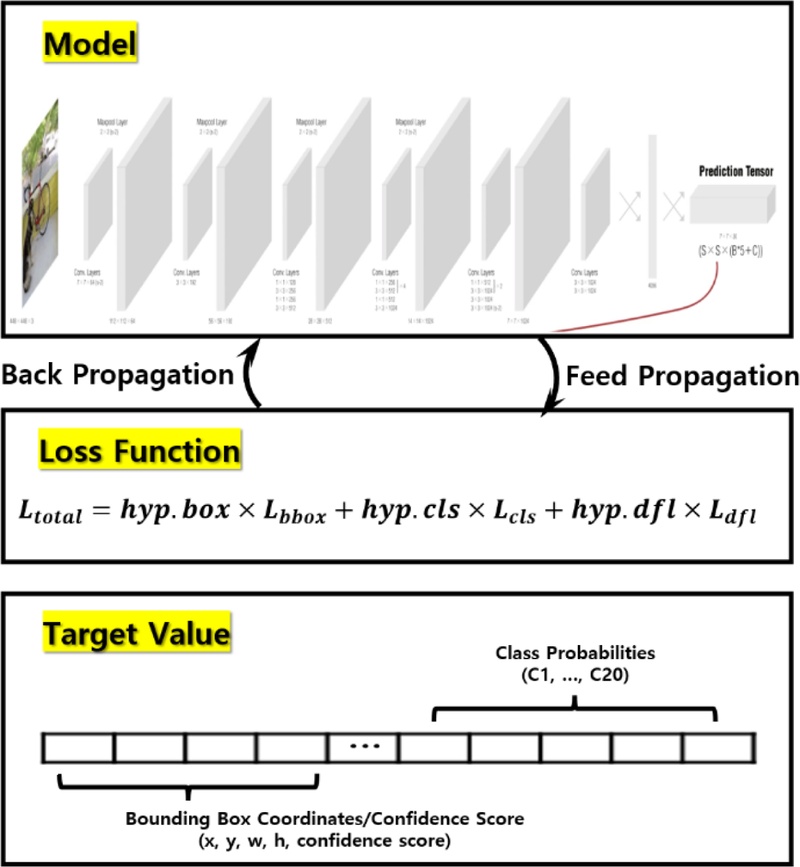
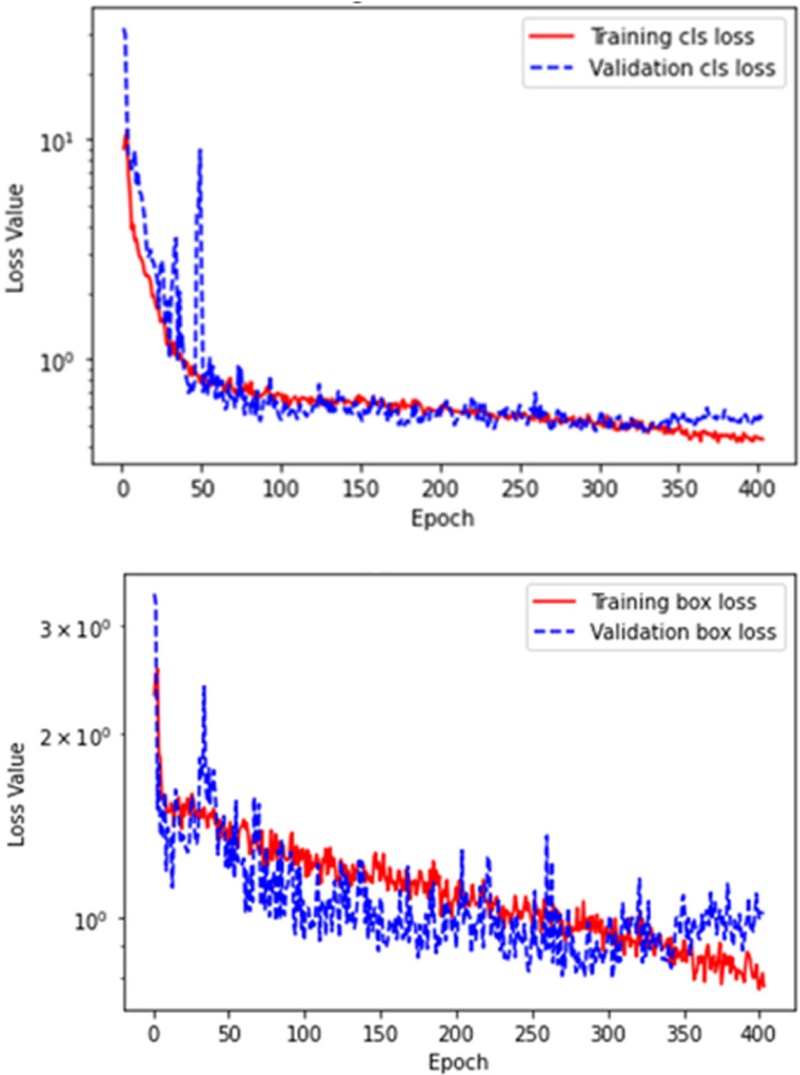
Fig. 8Loss of train set and valid set in YOLO models

YOLO 모델 학습의 손실은 변동을 보이며 지속적으로 감소하다 약 300 Epoch부터 검증 손실이 발산하기 시작하여 403 Epoch에서 조기 종료되었다. 따라서, YOLO를 활용한 관통 홀 검출 모델은 조기 종료를 통해 과적합이 발생하기 전 최적의 모델인 best.pt를 활용했다. 학습된 YOLO 모델을 이용한 관통 홀 검출은
Fig. 9에 설명되어 있다.
Fig. 9Hole detection results using YOLO method

그림에서 보는 바와 같이 왼쪽 영상에 제품 하부에 틈으로 비친 불빛이 존재하나 ‘YOLO Method’가 홀이 아님을 인지하고 홀로 검출하지 않았으며 오른쪽 영상에서 여러 개의 홀을 모두 검출했음을 확인할 수 있다. 또한, 이 방법은 입력된 이미지에서 관통 홀이 검출되면 홀이 포함된 Boundary Box의 위치 좌표와 Box에 대한 너비, 폭 정보를 제공한다. 이와 같은 특성을 이용하면 대상물 내에 홀의 존재 여부와 홀 위치 파악이 가능하다.
4.3 영상 처리 방법 비교 분석
영상 처리 방법별 관통 홀 검출 결과를 비교하기 위해 학습에 사용하지 않은 10개의 테스트 제품을 이용하여 관통 홀 검출 영상 처리 기법 3가지에 대한 성능을 비교했다. 데이터 세트 구축할 때와 동일한 환경에서 30 fps 속도로 영상 촬영했으며, 부트의 회전속도는 120 RPM이다. 1회전 당 하나의 Camera를 통해 15장 영상이 입력되고, 전체 Camera 수(4)를 고려하면 테스트 샘플 당 60장의 영상이 수집된다. 총 600장의 이미지에 대해 AI모델을 이용한 테스트 세트의 결함 검출 결과를 평가하기 위해 Confusion Matrix 형태로 표시하면
Table 2 및
3과 같다.
Table 2Confusion matrix of the test set in U-Net method
Table 2
|
U-Net |
Predict |
|
P |
N |
|
Actual |
P |
13 (TP) |
5 (FN) |
|
N |
4 (FP) |
578 (TN) |
[Performance]
Accuracy = (13 + 578) / (5 + 4 + 13 + 578) = 0.985
Precision = 13 / (13 + 4) = 0.765
Recall = 13 / (13 + 5) = 0.722
F1 score = (2 * 0.765 * 0.722) / (0.765 + 0.722) = 0.743 |
Table 3Confusion matrix of the test set in YOLO method
Table 3
|
YOLO |
Predict |
|
P |
N |
|
Actual |
P |
16 (TP) |
4 (FN) |
|
N |
0 (FP) |
580 (TN) |
[Performance]
Accuracy = (16 + 580) / (0 + 4 + 16 + 580) = 0.993
Precision = 16 / (16 + 0) = 1.000
Recall = 16 / (16 + 4) = 0.800
F1 score = (2 * 1.000 * 0.800) / (1.000 + 0.800) = 0.889 |
120 RPM 속도로 CV조인트 부트를 회전시킬 때, 영상 촬영 속도가 fps = 30이면 제품은 프레임 당 24o로 회전한다. 이 때, 360o 중 일부 각도에서 관통홀이 나타나기 때문에, 600장 테스트 이미지에서 TN의 비율은 상대적으로 높다.
Table 2 및
3을 통해 도출할 수 있는 성능 지표로 Accuracy(정확도), Precision(정밀도), Recall(재현율), F1 Score가 있다.
Accuracy는 전체 샘플 중에서 모델이 올바르게 예측한 샘플의 비율로, 분류 성능을 평가하는 가장 단순한 지표이다. Precision은 모델이 Positive로 예측한 샘플 중 실제로 Positive인 샘플의 비율로 정의되며, 이는 Gap을 관통홀로 오인하지 않았는지를 나타낸다. Recall은 실제 Positive 샘플 중에서 모델이 Positive로 올바르게 예측한 비율로, 관통홀이 있는 경우 이를 빠짐없이 검출했는지를 나타낸다. F1 Score는 Precision과 Recall에 대한 조화 평균으로 정의되며, Precision과 Recall 성능 지표를 동시에 고려할 수 있는 지표이다.
Table 2 및
3의 결과를 바탕으로 성능을 분석하면 ‘U-Net Method’ 정확도는 0.985, ‘YOLO Method’ 정확도는 0.993으로 두 방법 모두 높은 정확도를 보이며 큰 차이가 없다. 그러나, Precision, Recall, F1 Score의 관점에서 ‘YOLO Method’가 더 우수한 성능을 보였다.
구체적으로 ‘U-Net Method’는 Precision 0.765, Recall 0.722, F1 Score 0.743을 기록한 반면, ‘YOLO Method’는 Precision 1.000, Recall 0.800, F1 Score 0.889로 나타났다.
각 방법에 대한 테스트 제품 10개에 대한 관통홀 최종 검출 성능은
Table 4와 같다.
Table 4Hole detection performance of the various image processing techniques
Table 4
|
Test sample |
Final result |
|
No. |
# of
holes |
Gap |
IS |
AI model |
|
U-Net |
YOLO |
|
1 |
0 |
N |
○: 1 / ×: 3 |
○: 0 / ×: 4 |
○: 0 / ×: 4 |
|
2 |
0 |
N |
○: 1 / ×: 3 |
○: 0 / ×: 4 |
○: 0 / ×: 4 |
|
3 |
0 |
Y |
○: 1 / ×: 3 |
○: 1 / ×: 3 |
○: 0 / ×: 4 |
|
4 |
0 |
Y |
○: 1 / ×: 3 |
○: 1 / ×: 3 |
○: 0 / ×: 4 |
|
5 |
1 |
N |
○: 1 / ×: 3 |
○: 0 / ×: 4 |
○: 0 / ×: 4 |
|
6 |
1 |
Y |
○: 3 / ×: 1 |
○: 3 / △: 1 |
○: 4 / ×: 0 |
|
7 |
3 |
Y |
○: 3 / ×: 1 |
○: 3 / △: 1 |
○: 4 / ×: 0 |
|
8 |
2 |
N |
△: 3 / ×: 1 |
△: 3 / ○: 1 |
○: 2 / △: 2 |
|
9 |
1 |
N |
△: 3 / ×: 1 |
○: 2 / △: 2 |
○: 2 / △: 2 |
|
10 |
1 |
N |
○: 3 / ×: 1 |
○: 4 / ×: 0 |
○: 4 / ×: 0 |
분석 결과, 3가지 방법 모두 카메라 위치에 따라 관통 홀 검출 결과가 달라짐을 알 수 있다. 이를 설명하기 위해 각 영상처리 기법별 잘 분류된 예시와 오분류된 예시를 제시하면
Figs. 10-
12와 같다.
Fig. 10Well-classified (left) and mis-classified (right) examples obtained by IS method

‘IS Method’는 검사 샘플 내의 관통 홀 존재 여부만을 파악할 수 있기 때문에 홀이 2개 이상 존재하거나 관통홀과 틈새로 인한 불빛이 동시에 존재하는 경우에도 관통홀이 1개 존재하는 것과 같은 결과를 출력한다. 또한,
Fig. 10에서 확인할 수 있듯이 합산된 이미지에는 여러 각도에서 수집된 이미지가 중첩되어 나타나기 때문에 부트 내 관통홀이 존재하는 높이 파악은 가능하지만 정확한 각도 파악이 어렵다. 그러나, 제품이 달라져도 같은 카메라 위치에서 주위 배경 환경은 일정하기 때문에 동일한 검출 결과를 도출함을 확인할 수 있다.
‘U-Net Method’는 ‘IS Method’에 비해 관통 홀 존재를 정확하게 탐지하는 것과 더불어 관통 홀의 개수, 입력 이미지에서 관통홀의 위치 정보를 확인할 수 있다. 하지만,
Fig. 11에서 확인할 수 있듯이 빛이 누출되는 틈새를 관통 홀로 오검출하는 문제가 있었다. 또한, 관통홀이 2개 이상 존재하는 경우, 관통홀을 하나만 검출하고 나머지 관통홀을 검출 못하는 문제가 있었다. 이를 통해 ‘U-Net Method’은 학습 데이터가 아닌 새로운 데이터에 대한 예측 능력인 일반화 성능이 취약하다는 것을 확인할 수 있다.
Fig. 11Well-classified (top) and mis-classified (middle, bottom) examples obtained by U-Net method

‘YOLO Method’는 다른 두 방법과 달리 빛이 누출되는 틈새를 관통홀로 오검출하는 문제가 없었다. 또한, ‘U-Net Method’에 비해 관통 홀 개수를 정확하게 탐지함을 확인할 수 있었다. 따라서,
Fig. 12와 같이 카메라 위치에 따라 일부 관통홀을 검출 못하는 문제도 존재하지만 ‘YOLO Method’는 ‘U-Net Method’에 비해 상대적으로 일반화 성능이 우수함을 확인할 수 있다.
Fig. 12Well-classified (left) and mis-classified (right) examples obtained by YOLO method

실험 진행 중 time 라이브러리에 있는 time.time() 메소드를 이용하여 각 방법의 실행 시간을 측정한 결과는
Fig. 13에 설명되어 있다. 또한, 이를 바탕으로 전체 프로그램의 Run Time을 구하면
Fig. 14와 같은 결과를 얻을 수 있다.
Fig. 13Execution time for each technique [Unit: sec]
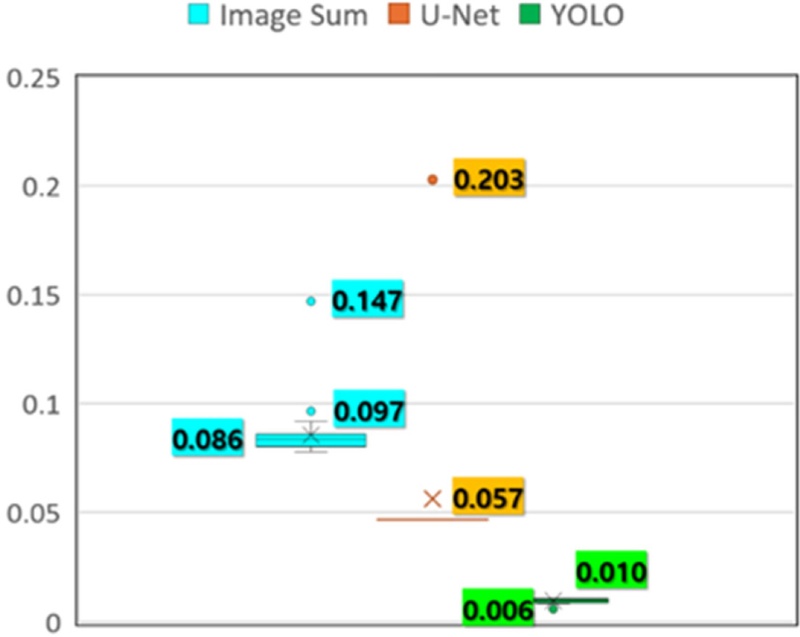
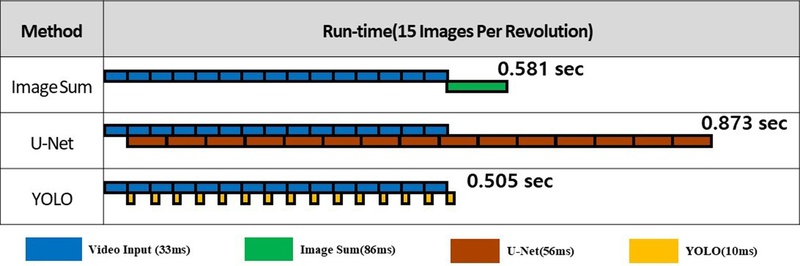
Fig. 14Run-time for hole detection of 3 methods

‘IS Method’는 한 바퀴 회전하면서 메모리에 입력 이미지를 저장하고 회전이 완료되면 이미지 합산 및 관통 홀 검출 작업을 진행한다. 따라서, 실행 시간은 촬영 속도에 영향을 받게 된다.
‘U-Net Method’는 이미지 한 장 단위로 관통 홀 검출을 수행하므로 다음 영상이 입력되기 전에 U-Net 모델을 이용한 관통홀 검출을 수행할 수 있다. 하지만, U-Net 연산 속도는 평균 56 ms(약 18 fps)로 영상 입력 속도 33 ms (30 fps)에 비해 느리므로 영상 입력 속도를 18 fps 이하로 낮춰야 한다.
‘YOLO Method’ 역시 이미지 한 장 단위로 관통 홀을 검출하므로 영상 입력 간격이 검출 시간보다 크면 다음 프레임이 입력되기 전 탐지를 완료할 수 있다. ‘YOLO Method’의 검출 속도는 10 ms (100 fps)로 영상 입력 속도에 비해 빨라 영상 입력 속도를 100 fps까지 높일 수 있다. 각 기법을 ‘관통 홀 검출 정확도’, ‘틈새로 인한 오판단 여부’, ‘결함 추론에 소요되는 시간’ 관점에서 분석한 결과가
Table 5에 설명되어 있다.
Table 5Hole detection performances for 3 techniques
Table 5
|
Method |
IS |
U-Net |
YOLO |
|
Accuracy |
Low |
High |
Very high |
Misdetection
rate |
High |
Medium |
Low |
Processing
time |
After Final
frame |
56ms
(18 fps) |
10ms
(100 fps) |
Table 5에서 알 수 있는 바와 같이 ‘YOLO Method’가 가장 적합한 것으로 판단되어 관통 홀 검출 시스템에 활용할 최종 모델로 선정했다.
5. 결론
본 논문에서는 자동차 CV 조인트 부트의 제조 품질 향상을 위한 관통 홀 검출 시스템의 성능을 개선하는 영상 처리 기법을 제안하였다. 기존의 수작업 검사 방식은 효율성과 신뢰성이 낮으며, 검사자의 주관된 판단에 따라 오류가 발생할 가능성이 높다. 이를 해결하기 위해 영상 처리 기술을 활용한 자동화된 결함 탐지 기법을 개발하고, 다양한 방법을 비교하여 최적의 기법을 도출하였다. 먼저, 기존의 IS Method와 딥러닝 기반 모델(U-Net, YOLO)을 정확도와 실행 시간 측면에서 비교 분석한 결과, YOLO 모델이 가장 우수한 성능을 보였으며, 영상 처리 속도 또한 매우 빠르다는 것을 확인하였다. 또한, YOLO 모델은 기존 방법 대비 검출 속도가 빠르면서도 학습을 통해 틈새로 누출된 빛을 오검출하는 문제가 없으며, 다양한 환경에서 안정적인 성능을 제공한다.
본 연구에서 영상처리와 인공지능을 결합한 관통홀 탐지법의 우수한 성능을 확인하였다. 하지만 정해진 실험 환경에서 탐지 성능을 검토하였으므로 향후 다양한 제조 환경에서의 적용성과 확장성을 검토할 필요가 있다. 특히, 실제 생산 과정에서 발생할 수 있는 조명 변화, CV 조인트 부트의 변형, 오염 등의 변수가 존재하는 다양한 환경에서의 성능을 평가하고 시스템을 최적화하는 연구가 필요하다. 아울러, 제조 과정의 관통 홀 발생에 대한 원인 분석과 개선 방안 검토를 위해 부트 내부 홀 위치를 정확히 검출하는 방법에 대한 검토도 필수적이다.
REFERENCES
- 1.
Dikici, S., Robinson, R. J., (2024), Automated defect detection using image recognition in manufacturing, Journal of Data Science and Intelligent Systems.
10.47852/bonviewJDSIS42023833
- 2.
Kazmi, M., Hafeez, B., Aftab, F., Shahid, J., Qazi, S. A., (2023), A deep learning-based framework for visual inspection of plastic bottles, IEEE Access, 11, 125529-125542.
10.1109/ACCESS.2023.3329565
- 3.
Maruthi, M., Kim, B., (2023), Preprocessing and image enhancement techiques, Construction Engineering and Management, 24(3), 25-28.
- 4.
D’Angelo, G., Rampone, S., (2016), Feature extraction and soft computing methods for aerospace structure defect classification, Measurement, 85, 192-209.
10.1016/j.measurement.2016.02.027
- 5.
Tsai, D.-M., Lin, B.-T., (2002), Defect detection of gold-plated surfaces on pcbs using entropy measures, The International Journal of Advanced Manufacturing Technology, 20(6), 420-428.
10.1007/s001700200172
- 6.
Fu, G., Jia, S., Zhu, W., Yang, J., Cao, Y., Yang, M. Y., Cao, Y., (2022), Fusion of multi-light source illuminated images for effective defect inspection on highly reflective surfaces, Mechanical Systems and Signal Processing, 175, 109109.
10.1016/j.ymssp.2022.109109
- 7.
Hou, M., Li, P., Cheng, S., Yv, J., (2024), Cnn‐based defect detection in manufacturing, Advanced Control for Applications: Engineering and Industrial Systems, 6(4), e196.
10.1002/adc2.196
- 8.
Cheng, J., Guo, B., Liu, J., Liu, S., Wu, G., Sun, Y., Yu, Z., (2021), Tl-sdd: A transfer learning-based method for surface defect detection with few samples, Proceedings of the 7th International Conference on Big Data Computing and Communications (BigCom), Institute of Electrical and Electronics Engineers, 136-143.
10.1109/BigCom53800.2021.00023
Biography
- Yun-Hyeok Lim
M.S. candidate in the Department of Automotive Engineering, Kyungpook National University. His research interests include autonomous vehicles, vision algorithm, artificial intelligence, image processing etc.
- Hyeongill Lee
Professor in the School of Automotive Engineering, Kyungpook National University. His research interests are automotive NVH, sound radiation from vibration structure, image processing autonomous vibrating, etc.