ABSTRACT
Manufacturing systems are increasingly required to operate in high-mix, low-volume production environments, where process flexibility is crucial. One effective way to achieve this flexibility is through the use of multiple processing alternatives (MPA), allowing a product to be produced using different process plans or component structures. In MPA environments, scheduling decisions must address both the selection of processing alternatives for each product and the execution order of the resulting production tasks. Additionally, processing times often vary due to machine conditions and process variability, further complicating scheduling. This study introduces a dual-network-based deep reinforcement learning method for scheduling in manufacturing systems with multiple processing alternatives. The framework utilizes two Q-networks to learn both the selection of processing alternatives and the dispatching rules. Computational experiments demonstrate that the proposed method effectively reduces both the average makespan and its variability compared to a genetic algorithm-based approach, particularly as the problem size increases, showcasing its effectiveness in the face of processing time uncertainty.
-
KEYWORDS: Manufacturing systems, Multiple processing alternatives, Deep reinforcement learning, Manufacturing scheduling, Process flexibility, Artificial intelligence
-
KEYWORDS: 심층 강화학습, 생산제조 시스템, 다중공정대안, 제조 스케줄링, 공정 유연성, 인공지능
NOMENCLATURE
Weight Vector of Q-network 1
Weight Vector of Target Q-network 1
Weight Vector of Q-network 2
Weight Vector of Target Q-network 2
Replay Buffer of Q-network 1
Replay Buffer of Q-network 2
Number of Decision Period
Action of Q-network 1 at Decision Period t
Action of Q-network 2 at Decision Period t
State of Environment at Decision Period t
State of Environment at Decision Period t after Conducting a1,t
Reward at Decision Period t
1. 서론
최근 제조 산업은 고객 맞춤형 제품 수요 증가와 제품 수명 주기의 단축으로 인해 다품종 소량생산 환경으로 빠르게 전환되고 있다. 이러한 변화는 생산 시스템이 기존의 대량생산 중심 구조에서 벗어나 다양한 제품 요구에 유연하게 대응할 수 있는 공정 유연성(Process Flexibility)을 갖출 것을 요구한다. 특히 스마트 제조와 자율제조 기술의 발전은 생산 시스템이 변화하는 생산 요구와 운영 조건에 적응적으로 대응할 수 있는 의사결정 능력을 갖추는 것을 중요한 과제로 만들고 있다.
이러한 제조 환경에서 생산 유연성을 확보하기 위한 중요한 방법 중 하나는 동일한 작업을 서로 다른 공정 방식 또는 설비를 통해 수행할 수 있도록 하는 것이다. 이를 반영한 개념이 다중공정대안(Multiple Processing Alternatives, MPA)이며, 이는 하나의 작업이 수행될 수 있는 여러 공정대안이 존재하는 생산 환경을 의미한다. Kim과 Kim은 이러한 개념을 고려한 병렬기계 스케줄링 문제를 제시하고 공정대안 선택과 작업 스케줄링 의사결정을 동시에 고려해야 하는 새로운 스케줄링 구조를 제안하였다[
1]. MPA 환경에서는 작업이 어떤 공정 대안을 선택하는가에 따라 처리시간과 자원 사용 패턴이 달라지기 때문에 공정 대안 선택과 작업 스케줄링 의사결정을 통합적으로 고려하는 접근이 필요하다.
한편 실제 제조 시스템에서는 작업의 처리시간이 사전에 정확하게 결정되지 않는 경우가 많다. 설비 상태, 공정 조건, 작업자 숙련도, 재료 특성 등 다양한 요인에 의해 공정시간, 셋업시간, 조립시간과 같은 공정 시간이 변동성을 가지며, 이러한 시간적 불확실성은 생산 시스템의 운영 성능에 직접적인 영향을 미친다. 특히 MPA 환경에서는 선택된 공정대안에 따라 처리시간의 분포가 달라질 수 있기 때문에 스케줄링 의사결정의 복잡성이 더욱 증가하게 된다.
전통적인 제조 스케줄링 연구에서는 이러한 문제를 해결하기 위해 수리적 최적화 방법이나 다양한 휴리스틱 및 메타휴리스틱 기반 접근이 활용되어 왔다. 특히 유전알고리즘, 타부탐색, 시뮬레이티드 어닐링과 같은 방법들은 복잡한 스케줄링 문제에서 우수한 해를 도출할 수 있는 방법으로 널리 연구되어 왔다[
2,
3]. 그러나 이러한 방법들은 일반적으로 새로운 문제 인스턴스가 주어질 때마다 반복적인 탐색 과정이 필요하며, 처리시간 변동이나 설비 상태 변화와 같은 불확실성이 존재하는 제조 환경에서는 스케줄을 반복적으로 재계산해야 하는 한계를 갖는다.
최근에는 이러한 한계를 극복하기 위해 강화학습(Reinforcement Learning) 기반 접근이 제조 스케줄링 문제 해결에 활용되고 있다. 강화학습은 환경과의 상호작용을 통해 의사결정 정책을 학습하는 방법으로, 불확실성이 존재하는 환경에서 반복적인 경험을 통해 효율적인 정책을 학습할 수 있다는 장점을 갖는다. 특히 심층 신경망을 활용한 Deep Reinforcement Learning (DRL) 기법은 복잡한 상태 공간을 갖는 조합 최적화 문제에 적용되면서 제조 스케줄링 문제에서도 다양한 연구가 진행되고 있다[
4,
5].
그러나 기존의 강화학습 기반 스케줄링 연구 대부분은 작업 선택 또는 기계 선택과 같은 단일 의사결정 문제에 초점을 두고 있으며, 공정대안 선택과 작업 스케줄링 의사결정이 동시에 존재하는 MPA 환경을 직접적으로 다룬 연구는 제한적이다. 이러한 환경에서는 먼저 작업이 수행될 공정대안을 선택해야 하며, 이후 선택된 공정대안을 기반으로 작업의 실행 순서를 결정해야 한다. 따라서 공정대안 선택과 작업 스케줄링 의사결정을 동시에 고려할 수 있는 새로운 스케줄링 접근이 필요하다.
본 연구에서는 MPA 환경을 고려한 제조 시스템 스케줄링 문제를 해결하기 위해 Dual-network 기반 심층 강화학습 방법을 제안한다. 제안된 방법은 두 개의 Q-network를 활용하여 공정대안 선택과 작업 스케줄링 의사결정을 각각 학습하도록 설계되었다. 첫 번째 네트워크는 작업이 선택할 공정대안을 결정하며, 두 번째 네트워크는 선택된 공정대안을 기반으로 디스패칭 규칙을 선택하여 작업의 실행 순서를 결정한다.
또한 본 연구에서는 제조 시스템의 운영 효율을 반영하기 위해 조립라인 가동률(Assembly Line Operating Ratio)과 생산완료율(Production Completion Ratio)을 보상 함수로 활용하여 학습을 수행한다. 이러한 보상 구조는 조립 라인의 유휴 시간을 최소화하고 각 시점의 완제품 생산 완료율을 향상시키는 방향으로 스케줄링 정책을 학습하도록 하며, 결과적으로 생산 완료 시간을 단축하는 효과를 유도한다.
본 연구의 주요 기여는 다음과 같다. 첫째, MPA를 고려한 제조 스케줄링 문제에서 생산 불확실성을 고려하는 강화학습 기반 스케줄링 프레임워크를 제안하였다. 둘째, 공정대안 선택과 디스패칭 규칙 선택을 각각 학습하기 위한 Dual-network 구조의 심층 강화학습 모델을 설계하였다. 셋째, 다양한 실험을 통해 제안된 방법이 제조 시스템의 운영 효율을 향상시키는 스케줄링 정책을 학습할 수 있음을 확인하였다.
본 논문의 구성은 다음과 같다. 2장에서는 관련 연구를 검토하고, 3장에서는 MPA를 고려한 제조 스케줄링 문제를 정의한다. 4장에서는 제안하는 Dual-network 기반 심층 강화학습 방법을 설명한다. 5장에서는 실험 설계 및 결과를 제시하고, 마지막으로 6장에서 결론 및 향후 연구 방향을 제시한다.
2. 관련연구
2.1 공정 유연성과 다중공정대안을 고려한 스케줄링
제조 시스템의 유연성이 중요해지면서, 동일 작업을 서로 다른 공정 경로 또는 공정 계획으로 처리할 수 있는 환경을 고려한 스케줄링 연구가 꾸준히 수행되어 왔다. 이러한 연구는 일반적으로 Alternative Routing, Alternative Process Plans, Flexible Routing 등의 개념으로 전개되어 왔으며, 공정 계획 선택과 자원 할당, 작업 순서 결정을 통합적으로 다루는 것이 핵심이다. Čapek 과 Vanhoucke는 대안 공정계획(Alternative Process Plans)을 포함하는 생산 스케줄링 문제를 정식화하고, 공정 계획 선택과 스케줄링을 동시에 고려하는 수리모형과 해법을 제시하였다[
6]. Moon 등은 작업의 부하(Workload)와 자원 배분을 함께 고려하는 진화적 접근을 통해, 공정 선택과 자원 할당의 결합이 생산 성능에 미치는 영향을 분석하였다[
7].
이러한 연구 흐름 위에서 Kim과 Kim은 병렬기계 스케줄링 문제에 MPA 개념을 명시적으로 도입하였다 [ 1 ]. 해당 연구에서는 하나의 작업을 완제품 형태로 처리하거나 여러 파트로 분할하여 처리할 수 있는 구조와 Sequence-dependent Setup Time을 동시에 고려하였으며, MIP와 휴리스틱을 통해 MPA가 makespan과 설비 활용에 미치는 효과를 분석하였다[
1]. 이어 Kim과 Kim은 동일 병렬 적층기계(Additive Machine) 환경에서 MPA를 고려한 Branch and Price 기반 최적해 도출 알고리즘을 제안하여, 공정대안 선택이 스케줄 구조 자체를 바꾸는 핵심 의사결정영 역임을 보였다[
8]. 다만 이들 연구는 주로 결정론적 환경에서의 최적화 또는 휴리스틱 탐색에 초점을 두고 있으며, 불확실성이 존재하는 제조 현장에서 이를 정책 형태로 학습하는 문제까지는 확장하지 않았다.
실제 제조 현장에서는 공정시간, 셋업시간, 조립시간 등이 고정 값으로 주어지지 않고 설비 상태, 공정 조건, 작업자 숙련도, 자재 특성 등에 따라 변동한다. 이에 따라 전통적인 확정적 스케줄링(Deterministic Scheduling)만으로는 현장 운영을 충분히 설명하기 어렵고, 확률적 스케줄링(Stochastic Scheduling), 동적 스케줄링(Dynamic Scheduling), 강건 스케줄링(Robust Scheduling) 등의 연구가 함께 발전해 왔다. 최근에는 다중 공정시간(Variable Processing Times), 설비고장, 수요변동과 같은 동적 이벤트를 강화학습을 통해 반영한 연구가 증가하고 있다. Zhang 등은 다중 공정시간을 갖는 동적 Flexible Job Shop Scheduling Problem (FJSP)을정의하고, PPO 기반 DRL을 통해 오프라인 학습과 온라인 적용이 가능한 정책을 제시하였다[
9]. Grumbach 등은 동적 Flow Shop에서 Baseline Schedule의 강건성과 안정성을 동시에 고려하는 DRL 기반 접근을 제안하였다[
10]. 또한 Yu 등은 처리시간이 시간에 따라 변동하고 신규 작업이 유입되는 동적 Job Shop Problem (JSP) 환경에서, 실시간 재스케줄링이 가능한 DRL 기반 정책을 제시하였다[
11]. 이러한 연구들은 불확실성이 존재하는 제조 환경에서는 단일 정적 스케줄보다 환경 변화에 적응하는 정책 기반 접근이 유효할 수 있음을 보여준다.
강화학습, 특히 DRL은 복잡한 상태공간을 갖는 제조 스케줄링 문제에서 최근 가장 활발히 적용되는 방법이다. 초기 연구들은 주로 작업 선택이나 기계 선택과 같은 단일 의사결정을 학습하는 데 초점을 두었으나, 최근에는 그래프 신경망, 이기종 그래프 표현(Heterogeneous Graph Representation) 등을 결합하여 보다 복잡한 FJSP와 동적 JSP를 다루고 있다. Zhang 등은 이접 그래프(Disjunctive Graph)와 DRL을 이용해 우선순위 규칙을 자동 학습하는 접근을 제시하였고, 고정형 PDR 대비 우수한 일반화 성능을 보고하였다[
12]. Wan 등은 Meta-path 기반 이기종 그래프 인공신경망을 활용한 End-to-end DRL 방법을 통해 FJSP의 모델링 정확도와 정책 일반화 성능을 향상시켰다[
13]. 또한 동적 FJSP에서 임의의 주문 추가(Random Job Arrival)를 고려한 DRL 접근도 제안되어, 실시간 제조 스케줄링에서 RL 기반 정책의 실용 가능성을 보여주었다 [
14]. 이들 연구는 DRL이 단순 탐색을 넘어서, 다양한 제조 상태에 대응하는 정책(Policy) 자체를 학습할 수 있다는 장점을 보여준다.
복잡한 스케줄링 문제에서 DRL의 학습 안정성과 해석 가능성을 높이기 위해, 의사결정을 둘 이상의 단계로 분해하는 접근도 제안되고 있다. Li 등은 납기와 제품군 전환 셋업(Family Setups)을 고려한 병렬기계 스케줄링에서 Two-stage RNN 기반 DRL 구조를 제안하였으며, 상이한 의사결정을 단계적으로 분리함으로써 총 지연시간 최소화 성능을 향상시켰다[
15]. 이러한 연구는 복합 의사결정을 단일 행동 공간(Action Space)으로 직접 다루기보다, 하위 의사결정으로 분해하여 학습하는 구조가 효과적일 수 있음을 보여준다.
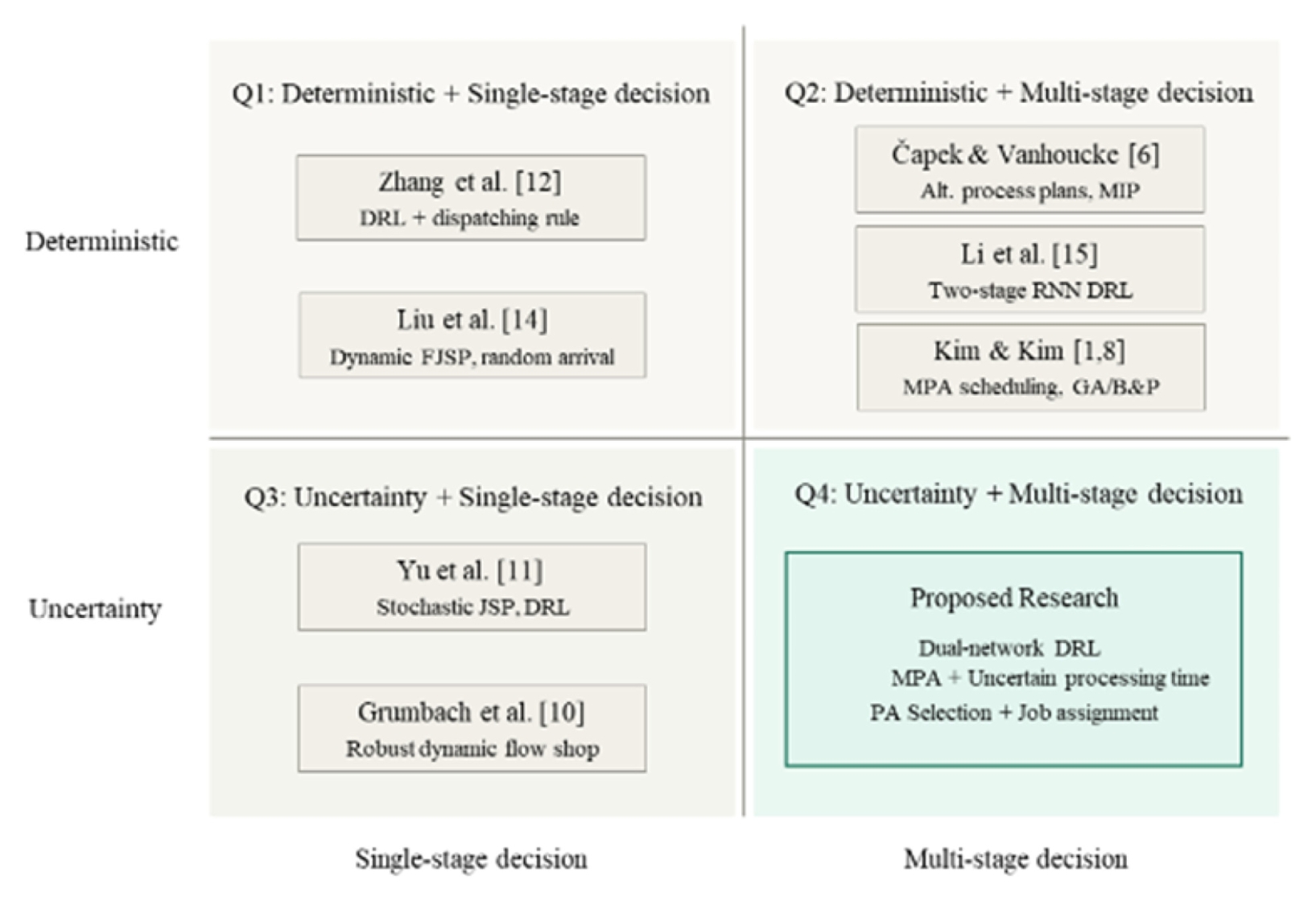
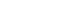
그러나 기존 연구를 종합하면, 첫째 공정 유연성을 고려한 연구들은 주로 대안공정계획 또는 MPA를 정적 최적화 문제로 다루었고[
1,
6,
8], 둘째 불확실성을 고려한 DRL 연구들은 주로 동적 FJSP나 JSP에서 작업 선택 또는 기계 선택 중심의 정책 학습에 초점을 두었다[
9-
11,
13,
14]. 다시 말해, MPA가 존재하는 제조 시스템에서 공정대안 선택과 작업 스케줄링 의사결정을 동시에 고려하면서, 시간적 불확실성에 대응할 수 있는 DRL 프레임워크는 충분히 다루어지지 않았다. 특히 공정 대안 선택과 디스패칭 규칙 선택을 각각 별도의 네트워크로 학습하는 Dual-network 구조는 기존 문헌에서 거의 확인되지 않는다. 따라서 본 연구는 MPA 기반 제조 환경에서 공정 대안 선택과 디스패칭 규칙 선택을 분리하여 학습하는 Dual-network DRL 접근을 제안함으로써, 기존 MPA 스케줄링 연구와 불확실성을 고려한 DRL 기반 동적 스케줄링 연구 사이의 공백을 메우고자 한다.
Fig. 1은 기존 연구들과 본 연구의 위치를 직관적으로 비교한 포지셔닝 개념도를 나타낸다. 기존 MPA 스케줄링 연구들은 대부분 결정론적 환경에서의 최적화 또는 휴리스틱 기반 단일 의사결정 구조에 집중되어 있으며, 불확실성을 고려한 DRL 연구들은 주로 동적 JSP/FJSP에서의 단일 의사결정(작업 선택 또는 기계 선택)을 학습 대상으로 삼고 있다. 반면, 본 연구는 처리시간 불확실성이 존재하는 MPA 환경에서 공정대안 선택과 디스 패칭 규칙 선택이라는 두 수준의 의사결정을 분리된 네트워크로 동시에 학습하는 프레임워크를 제안함으로써, 기존 연구들이 다루지 못했던 공백 영역을 채우고 있다.
3. 문제 정의
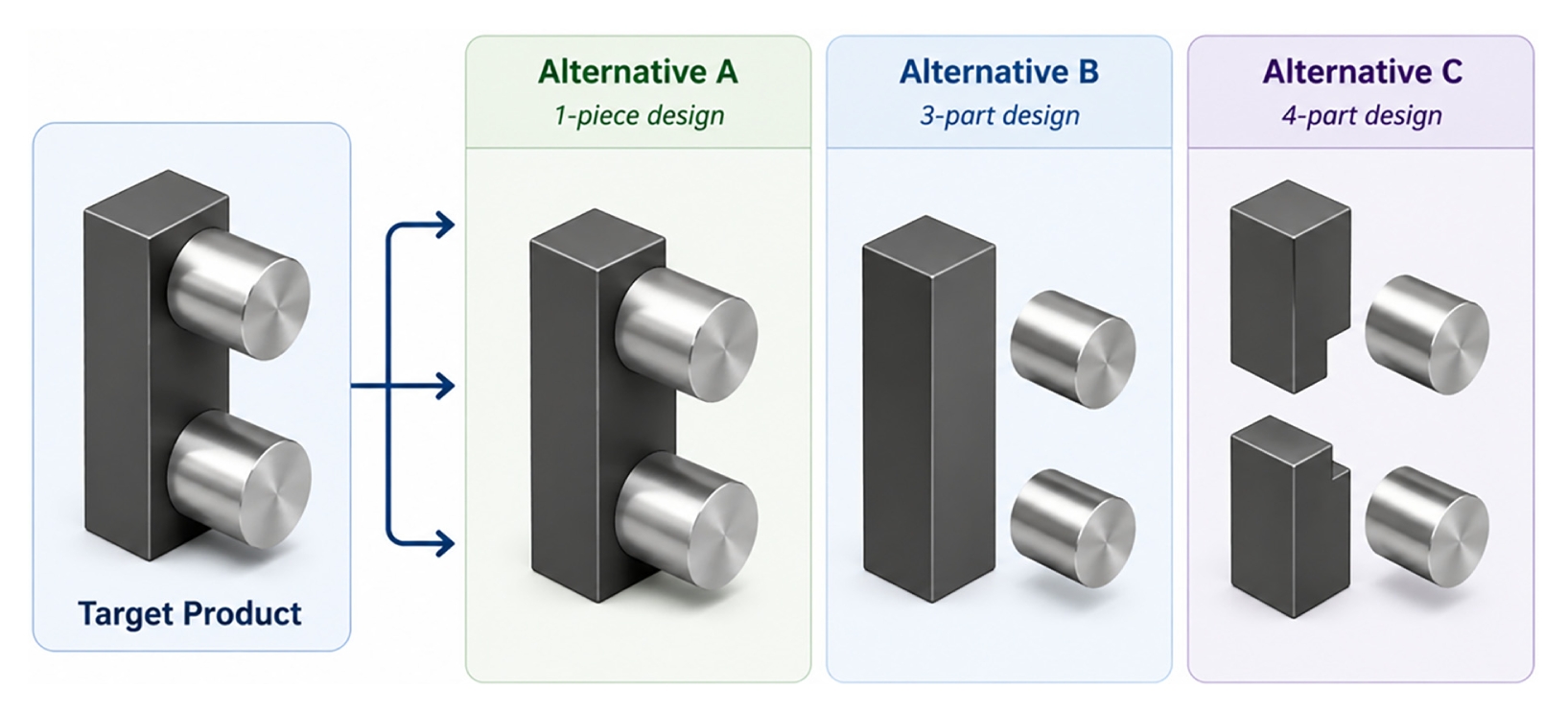
3.1 다중공정대안(MPA)
생산 대상 제품 집합을
F = {1,…,
F}라 하자. 각 제품
f는 하나의 완제품 형태로 생산될 수도 있고, 여러 개의 부품으로 분할 생산된 후 조립될 수도 있다. 즉, 각 제품은 복수의 공정대안을 가지며, 어떤 대안을 선택하는가에 따라 생산해야 할 부품의 구성과 수가 달라진다. 즉, 각 제품은 여러 개의 공정대안을 가지며,
l번째 대안은
l개의 부품으로 구성된다. 예를 들어,
Fig. 2와 같이 하나의 제품이 단일 완제품으로 직접 생산될 수도 있고, 세 개 혹은 네 개의 부품으로 분할 생산된 후 조립될 수도 있다.
이러한 구조는 제품의 생산 방식이 하나로 고정되지 않고, 시스템 상황에 따라 서로 다른 공정 대안을 선택할 수 있다는 점에서 제조 유연성을 반영한다. 본 연구에서 핵심 의사결정 중 하나는 각 제품에 대해 어떤 공정대안을 선택할 것인지 결정하는 것이다. 이 선택 결과에 따라 이후 생산 대상 부품 집합이 결정되며, 결과적으로 생산설비 부하와 조립 공정의 흐름도 달라지게 된다.
3.2 2단계 생산 프로세스 및 제약 조건
본 연구에서 고려하는 제조 시스템은 부품 생산 단계(Production Stage) 와 조립 단계(Assembly Stage) 로 구성된 2단계 생산 구조를 가진다. 각 단계의 시스템 구성과 작업 제약은 다음과 같다.
부품 생산 단계에는 M대의 병렬 생산 설비가 존재하며, 설비 집합은 m ∈ {1,…,M}로 표현된다. 선택된 공정 대안에 포함된 부품들은 이 단계에서 생산된다. 각 생산 설비는 한 시점에 하나의 부품만 처리할 수 있으며, 모든 작업은 비선점(Nonpreemptive) 방식으로 수행된다. 부품 j의 처리 시간은 pj로 나타내며, 작업 전환에 따른 준비 시간(Setup Time)은 sj로 정의한다. 실제 제조 환경에서 발생하는 공정 변동성을 반영하기 위해 처리 시간과 준비 시간은 일정 범위 내에서 변동될 수 있다고 가정한다.
조립 단계에는 A대의 조립 설비가 존재하며, 설비 집합은 a ∈ {1,…,A}로 표현된다. 제품 f의 조립 작업은 해당 제품을 위해 선택된 공정 대안 l에 포함된 모든 부품 j ∈ Jfl의 생산이 완료된 이후에 시작될 수 있다. 제품 f의 조립 시간은 gf로 정의하며, 생산 단계와 마찬가지로 실제 제조 공정의 불확실성을 반영하여 일정한 변동성을 가질 수 있다고 가정한다.
3.3 의사결정 구조 및 성능 평가 지표
본 연구에서 고려하는 스케줄링 문제는 공정대안 선택과 상세 스케줄링 등 두 개 수준의 의사결정으로 구성된다.
첫 번째 수준의 의사결정은 각 제품 f에 대해 적용할 공정 대안 l을 선택하는 것이다. 공정 대안이 결정되면 해당 대안에 포함된 부품 집합 Jfl이 확정되며, 이는 이후 부품 생산 단계에서 처리해야 할 작업 집합을 결정한다.
두 번째 수준의 의사결정은 확정된 부품들을 병렬 생산 설비에 할당하고 작업 순서를 결정하는 상세 스케줄링 과정이다. 본 연구에서는 생산설비에서 다음 작업을 선택하기 위한 방법으로 우선순위 규칙(Dispatching Rule) 기반 스케줄링을 사용한다. 구체적으로 SPT (Shortest Processing Time), LPT (Longest Processing Time) 등 여러 우선순위 규칙 중 하나를 선택하여 작업 순서를 결정하는 방식으로 스케줄링을 수행한다.
본 연구의 목적은 생산 단계와 조립 단계 간의 흐름 효율을 향상시키는 스케줄링 정책을 학습하는 것이다. 이를 위해 다음 두 가지 성능 지표를 기반으로 시스템 성능을 평가한다.
첫째, 조립 설비 가동률(Assembly Line Operating Ratio) 은 조립 설비가 실제로 작업을 수행하는 시간의 비율을 의미하며, 조립 공정의 활용도를 나타낸다.
둘째, 생산 완료율(Production Completion Ratio)은 해당 시점에 생산 완료된 완제품의 비율을 의미하며, 생산 시스템의 생산성 반영한다.
또한 본 연구에서 고려하는 스케줄링 문제는 기존의 병렬 기계 스케줄링 문제와 비교하여 다음과 같은 특징을 가진다. 첫째, 공정 대안 선택에 따라 생산해야 할 부품 집합이 달라지므로 설비 부하와 작업 구조가 동적으로 변화한다. 이로 인해 공정 대안 선택과 작업 스케줄링 의사결정 간에 강한 상호 의존성이 존재한다. 둘째, 실제 제조 환경에서는 처리 시간 및 준비 시간의 변동성이 존재하므로 단일 인스턴스에 대한 정적 스케줄을 도출하는 것보다 변화하는 상황에 적응 가능한 정책 기반 스케줄링 접근법이 요구된다.
4. Dual-network 기반 심층 강화학습
4.1 강화학습 아키텍처
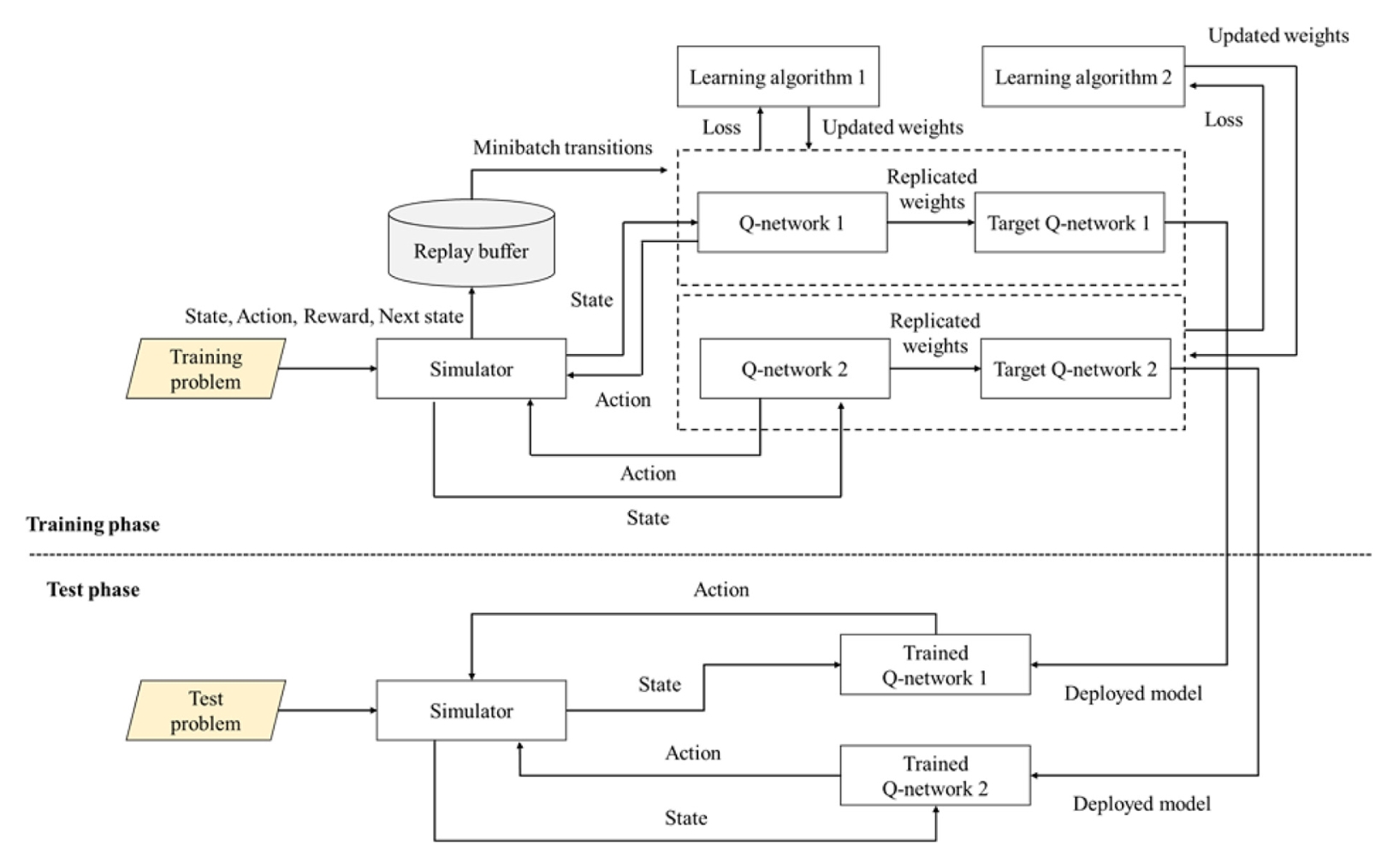
제안하는 강화학습 알고리즘은 Mnih et al. [
16]이 제안한 Q-network 아키텍처를 따른다. 이 아키텍처는 학습 단계(Training Phase) 와 테스트 단계(Test Phase)의 두 단계로 구성되며, 그 구조는
Fig. 3에 나타나 있다. 시뮬레이터는 상태를 생성하고 행동을 입력 받음으로써 제안된 문제의 환경을 반영하기 위한 이산 사건 시뮬레이션(Discrete Event Simulation)을 수행한다.
기존 아키텍처와 달리, 본 연구에서는 두 개의 Q-network를 고려한다. Q-network 1과 Q-network 2는 각각 제품의 공정 대안 선택(Processing Alternative Selection) 과 생산될 부품의 스케줄 결정을 담당한다.
학습 단계에서는 무작위로 생성된 다양한 문제 사례들을 활용하여 학습 알고리즘을 통해 Q-network들을 학습시킨다. 테스트 단계에서는 학습된 Q-network를 이용하여 테스트 스케줄링 문제를 해결한다. 또한 Q-network의 학습 효율성과 성능을 향상시키기 위해 재생버퍼(Replay Buffer)와 미니배치 전이(Mini-batch Transition) 개념을 적용하였다.
본 연구에서 두 개의 Q-network를 분리하여 설계한 것은 MPA 환경의 의사결정 구조적 특성을 반영한 것이다. 만약 공정 대안 선택(L가지 행동)과 디스패칭 규칙 선택(6가지 행동)을 단일 Q-network의 결합 행동 공간(Joint Action Space)으로 처리한다면, 행동 공간의 크기는 L × 6에 달한다. 예를 들어 L = 5인 경우 30개의 행동에 대한 Q-값을 동시에 추정해야 하며, 이는 Q-값 추정의 분산을 증가시키고 학습 샘플 효율을 저하시킨다. 본 연구의 Dual-network 구조는 이를 각각 3개 행동과 6개 행동의 두 독립적 학습 문제로 분해함으로써 각 Q-network가 더 단순한 행동 공간에서 안정적으로 수렴할 수 있도록 한다.
둘째, 두 의사결정의 발생 타이밍과 관련 상태 정보가 서로 이질적이다. 공정대안 선택(Q-network 1)은 아직 어떤 설비에도 부품이 할당되지 않은 제품을 대상으로 이루어지는 제품 수준(Product-level)의 의사결정이다. 반면 디스패칭 규칙 선택(Q-network 2)은 생산 설비가 유휴 상태가 될 때마다 발생하는 설비 수준(Machine-level)의 의사결정으로, 버퍼 내 부품 현황과 각 설비의 잔여 처리시간을 주된 판단 근거로 삼는다. 이 두 의사결정을 단일 네트워크에서 동일한 상태 입력으로 처리하면, 서로 다른 의사결정 맥락이 혼재되어 학습의 일관성이 저하될 수 있다. 별도 네트워크 구조는 각 결정 유형에 특화된 상태 표현을 독립적으로 학습하게 하여 이 문제를 완화한다.
셋째, 각 Q-network에 독립적인 Replay Buffer (D1, D2)를 운영함으로써, 두 의사결정 유형의 경험 전이(Transition) 분포가 서로 오염되지 않고 각자의 학습 패턴에 맞게 샘플링된다. 이는 공정대안 선택과 디스패칭 규칙 선택 사이의 강한 상관관계가 Q-값 추정 불안정으로 이어지는 것을 방지하는 효과를 갖는다.
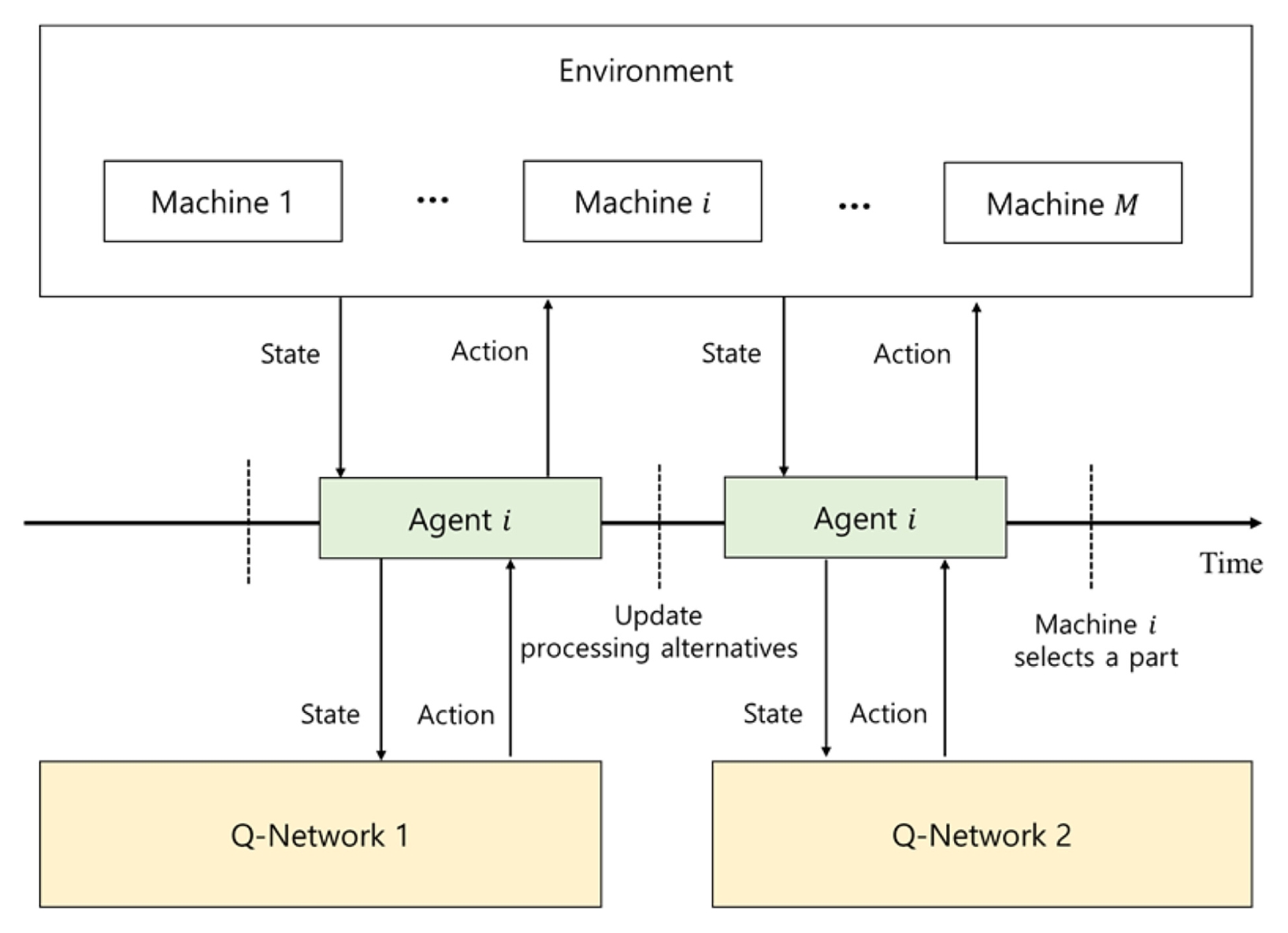
4.2 에이전트와 환경의 상호작용
제안된 강화학습 알고리즘에서 에이전트(Agent)는 각 생산 설비로 정의된다. 에이전트가 유휴 상태가 될 때마다 환경으로부터 상태 정보를 전달받으며, 에이전트는 이 상태 정보를 기반으로 행동을 선택한다. 이 상태 정보는 본 연구에서 정의한 제조 시스템을 반영한다.
한편, 조립 설비는 선입선출(First-in-first-out, FIFO) 규칙에 따라 작업을 수행한다고 가정한다. 따라서 본 연구에서는 생산 설비만을 에이전트로 간주한다. 예를 들어, 두 단계 사이의 버퍼에 위치한 모든 부품이 모이면 해당 제품은 그 순서대로 조립된다. 에이전트와 환경 간의 상호작용의 상세 구조는
Fig. 4에 나타나 있다.
에이전트와 환경 간의 상호작용은 두 개의 연속적인 시간 흐름(Two Consecutive Time Series)을 통해 이루어진다. 에이전트가 유휴 상태가 되면 환경은 상태 정보를 Q-network 1에 전달한다. Q-network 1은 아직 어떤 부품도 생산 설비에 의해 생산되지 않은 제품들에 대해 공정대안 선택(Processing Alternative Selection)을 갱신한다.
갱신된 공정 대안 선택은 즉시 환경에 반영되며, 이에 따라 상태 역시 갱신된다. 이후 갱신된 상태는 Q-network 2로 전달되며, Q-network 2는 유휴 상태의 생산설비에서 어떤 부품을 생산할 것인지를 결정한다. 만약 두 대 이상의 장비가 동시에 유휴 상태가 되면, 먼저 임의로 선택된 장비에 대한 의사결정을 수행하고, 다음으로 작업을 할당할 장비 역시 무작위로 선택된다.
4.3 상태, 행동 및 보상
4.3.1 상태(State)
제안된 강화학습 알고리즘에서 사용되는 상태들은
Table 1에 요약되어 있다. 상태는 다음 네 가지 그룹으로 구분된다. 첫 번째 그룹은 현재 공정 대안 선택에 의해 실현된 잔여 부품 처리 시간의 통계값을 포함하며, 평균값, 최대값, 최소값, 표준편차 등이 이에 해당한다. 두 번째 그룹은 아직 생산되어야 할 남은 제품 수, 현재 생산 중인 제품 수, 그리고 생산 설비에서 아직 생산되어야 할 남은 부품 수로 구성된다. 세 번째 그룹은 각 생산 설비와 조립 장비의 잔여 처리시간으로 구성된다. 마지막 그룹은 버퍼에 있는 부품과 제품의 정보를 포함한다. 여기에는 즉시 조립이 가능한 제품 수, 조립을 위해 1개의 부품이 더 필요한 제품 수, 2개의 부품이 더 필요한 제품 수, 3개의 부품이 더 필요한 제품 수가 포함된다. 또한 버퍼에 있는 제품들의 최대 조립시간과 최소 조립시간도 포함된다.
4.3.2 행동(Action)
제안된 강화학습 알고리즘의 두 Q-network는 서로 다른 행동 집합을 가진다. Q-network 1의 행동은 공정 대안 선택을 변경할 것인지, 그리고 어떤 방향으로 변경할 것인지를 결정한다. Q-network 1에는 다음의 세 가지 행동이 존재한다. 1) 현재 공정 대안 선택을 유지, 2) 실현된 부품 처리시간의 표준편차를 증가시키는 방향으로 공정 대안 선택 변경, 3) 실현된 부품 처리시간의 표준편차를 감소시키는 방향으로 공정 대안 선택 변경. 두 번째 또는 세 번째 행동이 선택되면
Figs. 5와
6에 제시된 알고리즘이 각각 수행된다.
Q-network 2의 행동은 유휴 상태의 생산 설비가 다음에 생산할 부품을 선택하기 위해 사용할 디스패칭 규칙(Dispatching Rule)을 선택하는 것이다. 본 연구에서는 다음의 여섯 가지 디스패칭 규칙을 고려하였다. 1) LPT (Longest Processing Time) 규칙, 2) SPT (Shortest Processing Time) 규칙, 3) LNPR (Least Number of Parts Remaining) 규칙, 4) MNPR (Most Number of Parts Remaining) 규칙, 5) LTPR (Least Time of Parts Remaining) 규칙, 6) MTPR (Most Time of Parts Remaining) 규칙.
LPT 규칙은 처리시간이 가장 긴 부품을 선택하며, SPT 규칙은 처리시간이 가장 짧은 부품을 선택한다. LNPR과 MNPR 규칙은 버퍼에 있는 제품 중 특정 제품을 선택한 후 해당 제품을 구성하는 부품 중 하나를 선택한다. LNPR 규칙은 조립을 위해 남아 있는 부품 수가 가장 적은 제품을 선택하고, MNPR 규칙은 남아 있는 부품 수가 가장 많은 제품을 선택한다. LTPR과 MTPR 규칙은 남은 부품 수 대신 잔여 처리시간을 기준으로 제품을 선택한다.
4.3.3 보상(Reward)
제안된 강화학습 알고리즘에서는 보상 함수를 도출하기 위해 조립 라인의 가동률과 현 시점의 생산 완료율 두 가지 지표를 고려한다. 조립 라인의 가동률은 모든 조립 설비에서 수행된 총 조립시간을 현재 시간과 조립 설비 수의 곱으로 나눈 값으로 계산된다. 생산 완료율은 완료된 제품 수를 전체 제품 수로 나눈 값으로 계산된다. 최종 보상 함수는 이 두 지표의 가중합(Weighted Sum)으로 계산된다. 각 학습 에피소드마다 환경을 초기화하고 초기 상태를 관측한다. 이후 각 의사결정 시점에서 ε-greedy 정책에 따라 행동을 선택한다. 선택된 행동은 환경에 전달되며, 새로운 상태와 보상이 반환된다. 이러한 경험 전이(Transition)는 재생버퍼(Replay Buffer)에 저장된다.
일정한 간격마다 재생버퍼에서 무작위로 미니배치를 추출하여 Q-network의 파라미터를 업데이트한다. 이러한 학습 과정을 반복하면서 Q-network는 점차적으로 더 높은 보상을 얻는 정책을 학습하게 된다.
4.4 Q-Network의 학습
제안된 강화학습 알고리즘의 Q-network 학습 절차는
Fig. 7에 나타나 있다. 학습 과정에서는 먼저 Q-network 1과 Q-network 2의 파라미터를 각각 무작위로 초기화한다. 이후 target Q-network를 초기화하고 재생버퍼를 생성한다. 각 학습 에피소드 마다 환경을 초기화하고 초기 상태를 관측하고, 이후 각 의사결정 시점에서 ε-greedy 정책에 따라 행동을 선택한다. 선택된 행동은 환경에 전달되며, 새로운 상태와 보상이 반환된다. 이러한 경험 전이(transition)는 재생버퍼에 저장된다. 일정한 간격마다 재생버퍼에서 무작위로 미니배치를 추출하여 Q-network의 파라미터를 업데이트한다. 이러한 학습 과정을 반복하면서 Q-network는 점차적으로 더 높은 보상을 얻는 정책을 학습하게 된다.
5. 수치실험 결과
본 장에서는 제안한 강화학습 기반 스케줄링 방법의 성능을 검증하기 위한 수치 실험 결과를 제시한다. 실험은 다양한 규모의 문제 인스턴스에 대해 수행되었으며, 제안된 방법의 강건성(Robustness)을 확인하기 위해 기존 방법과 비교 분석을 수행하였다.
5.1 실험 환경
수치실험은 본 연구와 같은 문제를 다룬 Kim and Kim [
1,
8]에서 활용된 소규모, 중규모, 대규모 세 가지 인스턴스 그룹 데이터 셋을 사용하여 수행하였다. 소규모 인스턴스에서는 생산 설비 수
M을 2와 3으로 설정하였고, 제품 수
F는 3, 5, 10, 15로 설정하였다. 중규모 인스턴스에서는
M을 5와 10으로 설정하였으며,
F는 20, 30, 50, 100으로 설정하였다. 대규모 인스턴스에서는
M을 15와 20으로 설정하였고,
F는 100, 150, 200으로 설정하였다.
공정 대안의 수 L은 2, 3, 5로 설정하였으며, 조립 설비 수 A는 2와 3으로 설정하였다. 각 제품의 대안 1에 대한 표준 처리시간은 1 00분에서 500분 사이에서 무작위로 생성하였다. 조립 시간은 해당 제품의 전체 처리시간 합의 10%로 설정하였다.
강화학습 알고리즘의 학습 파라미터는 Park et al. [
17]에서 사용된 설정과 동일하게 적용하였다. 또한 학습 과정에서는 각 부품의 처리시간에 대해 ±10% 범위의 변동성을 부여하였다.
모든 수치 실험은 Intel(R) Core(TM) i9-10900KF CPU (3.70 GHz)와 32GB 메모리를 갖는 개인용 컴퓨터에서 수행하였다. 각 실험은 통계적 신뢰성을 확보하기 위해 1 00회 반복 수행하였다.
5.2 비교 방법 및 평가지표
제안된 강화학습 알고리즘의 성능을 평가하기 위해 Kim과 Kim [
1]이 제시한 유전 알고리즘(GA) 기반 방법과 비교 실험을 수행하였다. 각 실험에서는 먼저 표준 공정시간을 기준으로 GA를 이용한 스케줄(Standard Schedule)을 도출하였다. 이후 처리시간 변동성이 발생하는 상황을 고려하기 위해 시뮬레이션을 수행하였다. 각 시뮬레이션 반복에서 처리시간은 ±10% 범위에서 무작위로 변동하도록 생성하였으며, 표준 스케줄을 그대로 적용했을 때의 makespan을 계산하였다.
이후 동일한 데이터 세트에 대해 제안된 강화학습 알고리즘을 적용하여 makespan을 계산하고 결과를 비교하였다. 성능 비교는 생산성을 나타내는 makespan의 평균값과 강건성을 나타내는 makespan 표준편차의 평균값 두 가지 지표를 기준으로 수행하였다.
5.3 실험 결과 및 분석
5.3.1 소규모 인스턴스
Tables 2와
3은 각각 A = 2와 A = 3인 경우의 소규모 인스턴스 결과를 나타낸다.
Table 2에서 확인할 수 있듯이 A = 2인 경우 제안된 강화학습 알고리즘을 적용했을 때 GA 대비 makespan 평균값과 표준편차가 모두 감소하였다. 평균 makespan 감소율은 평균 1.97%, 최대 3.39%, 최소 0.79%였다. 또한 makespan 표준편차는 평균 4.96% 감소하였다. 반면
A = 3 인 경우(
Table 3)에는 감소율이 다소 감소하였다. 평균 makespan 감소율은 1.33%, 표준편차 감소율은 3.65%였다. 이는 조립 설비 수가 증가할수록 처리시간 변동성이 시스템 makespan에 미치는 영향이 감소하기 때문으로 해석된다.
소규모 인스턴스에서 makespan 평균 감소율이 약 1-2% 수준에 그친 것은, 탐색 공간이 제한적인 소규모 문제에서는 GA도 준수한 초기 스케줄을 도출할 수 있기 때문이다. 그러나 처리시간 변동이 발생할 때 GA는 사전에 도출한 고정 스케줄을 그대로 적용하는 반면, 제안된 강화학습 방법은 각 의사결정 시점마다 현재 시스템 상태를 반영하여 정책을 즉각 적용한다. 이로 인해 절대적인 makespan 개선폭이 작더라도, makespan 표준편차 감소율이 평균 4.0-5.5%로 평균 개선율보다 유의미하게 높게 나타난다. 이는 제안된 방법이 불확실한 환경에서 강건한(Robust) 스케줄링 정책을 학습하고 있음을 시사한다.
또한 조립 설비 수(A)가 2에서 3으로 증가할 때 성능 개선폭이 다소 감소하는 것은, 조립 병렬도가 높아질수록 개별 부품의 처리시간 변동이 조립 단계의 병목으로 전파되는 효과가 완충되기 때문이다. 즉, A = 2 환경에서는 부품 생산 완료 시점의 분산이 조립 설비의 유휴 여부를 직접 결정하지만, A = 3 환경에서는 복수의 조립 설비가 유휴 시간을 분산 흡수하므로 공정 대안 선택의 영향력이 상대적으로 줄어들게 된다.
5.3.2 중규모 인스턴스
중규모 인스턴스의 실험 결과는
Tables 4와
5에 나타나 있다.
A = 2인 경우 평균 makespan 감소율은 6.63%, 표준편차 감소율은 9.32%였다. 반면 A = 3인 경우 평균 makespan 감소율은 5.13%, 표준편차 감소율은 8.35%였다. 소규모 인스턴스와 동일하게 조립 설비 수가 증가할수록 감소율이 다소 감소하는 경향을 보였다. 그러나 소규모 인스턴스와 비교하면 makespan 평균 감소율과 표준편차 감소율 모두 증가하였다. 이는 문제 규모가 증가할수록 제안된 강화학습 방법의 성능 향상 효과가 더욱 크게 나타남을 의미한다.
중규모 인스턴스에서 성능 개선폭이 소규모 대비 약 3-5배 증가한 것은 두 가지 이유로 설명할 수 있다. 첫째, 제품 수(F)와 설비 수(M)가 증가할수록 공정대안 선택과 디스패칭 규칙의 조합에 의한 탐색 공간이 지수적으로 커진다. GA는 이 확장된 탐색 공간에서 반복 연산을 통해 하나의 고정 스케줄을 도출하지만, 각 시뮬레이션 반복에서 처리시간이 변동할 경우 사전 도출된 스케줄의 품질이 급격히 저하된다. 반면, 제안된 강화학습 방법은 다양한 처리시간 시나리오를 학습 과정에서 경험하였으므로, 변동이 발생하더라도 학습된 정책이 적응적으로 대응할 수 있다. 둘째, 공정대안 수(L)가 증가할수록 Q-network 1이 선택할 수 있는 대안의 범위가 넓어지므로, 실시간 상태 정보를 기반으로 한 유연한 공정대안 재선택의 효용이 더욱 커진다. 이는 L = 5 조건에서의 표준편차 감소율이 L = 2 조건에 비해 일관되게 높게 나타나는 결과와도 부합한다.
5.3.3 대규모 인스턴스
대규모 인스턴스의 실험 결과는
Tables 6과
7에 나타나 있다. 모든 대규모 인스턴스에서 제안된 강화학습 알고리즘은 GA와 비교하여 makespan 평균값과 표준편차 모두 감소하였다. A = 2인 경우 평균 makespan 감소율은 9.76%였으며, 최대 10.85%, 최소 8.47%였다. 또한 L = 3과 L = 5인 경우는 L = 2보다 평균 및 표준편차 감소율이 다소 증가하였다. A = 3인 경우 평균 makespan 감소율은 8.96%, 최대 10.57%, 최소 7.42%였다. makespan 표준편차 감소율은 평균 10.83%, 최대 12.81%, 최소 8.88%였다. 특히 소규모 및 중규모 인스턴스와 비교할 때 makespan 평균 감소율과 표준편차 감소율 모두 증가하였다. 이는 문제 규모가 증가할수록 제안된 강화학습 기반 스케줄링 방법이 기존 GA 기반 방법보다 더욱 큰 성능 이점을 제공함을 의미한다.
대규모 인스턴스에서 나타난 약 9 -1 1%의 makespan 평균 감소율과 10-15%의 표준편차 감소율은 단순한 탐색 품질의 차이를 넘어, 두 방법 간의 구조적 차이에 기인하는 것으로 해석된다. GA 기반 방법은 표준 처리시간을 기준으로 스케줄을 사전에 결정하므로, 대규모 문제에서 처리시간 변동이 발생할 경우 생산 설비 간 부하 불균형이 누적되고 조립 설비의 유휴 시간이 증가하는 경향이 있다. 이에 반해 제안된 방법은 각 의사결정 시점의 실제 상태(잔여 처리시간, 버퍼 내 부품 현황 등)를 상태 입력으로 활용하여 정책을 적용하므로, 처리시간 변동이 발생하더라도 조립 설비 가동률을 유지하는 방향으로 작업 순서를 동적으로 조정할 수 있다.
또한 대규모 인스턴스에서 공정대안 수(L)가 증가할수록(L=2 → L=5) 평균 및 표준편차 감소율이 다소 증가하는 경향이 관찰된다. 이는 선택 가능한 공정대안이 많을수록 Q-network 1이 현재 시스템 부하에 최적화된 대안을 선택할 여지가 커지기 때문이며, 공정 유연성이 높을수록 강화학습 기반 정책의 활용도가 높아짐을 보여준다. 이러한 결과는 제안된 방법이 다품종 소량 생산 환경의 공정 유연성을 효과적으로 활용할 수 있는 스케줄링 프레임워크임을 실증적으로 지지한다.
5.3.4 제안한 아키텍처 구성요소별 기여 분석
제안된 방법의 성능 향상은 Dual-network 구조, 보상 함수 설계, 상태 정의의 세 가지 구성 요소가 복합적으로 기여한 결과이다. 실험 설계상 각 요소를 독립적으로 분리한 소거 실험(Ablation Study)을 별도로 수행하지는 않았으나, 각 구성 요소의 역할을 개념적으로 구분하면 다음과 같다.
먼저 보상 함수 설계의 역할을 고려한다. 본 연구에서는 makespan을 직접 보상으로 사용하는 대신, 조립 설비 가동률과 생산 완료율의 가중합을 보상 신호로 정의하였다. 이 설계는 에피소드가 종료된 이후에만 성과를 평가하는 희소 보상(Sparse Reward) 문제를 완화하고, 각 의사결정 시점에서 즉각적인 피드백을 제공함으로써 학습 수렴을 촉진한다. 따라서 보상 함수 설계는 어떠한 네트워크 구조를 사용하더라도 공통적으로 학습 효율에 영향을 미치는 요소이며, Dual-network 구조와는 독립적으로 기여한다고 볼 수 있다.
다음으로 상태 정의의 역할을 고려한다. 본 연구의 상태는 잔여 부품 처리시간 통계값, 잔여 제품 및 부품 수, 각 설비의 잔여 처리시간, 버퍼 내 부품 및 제품 현황의 네 그룹으로 구성된다. 이 상태 정의는 생산 단계와 조립 단계 간의 흐름 상황을 포괄적으로 표현하도록 설계되었으며, 공정대안 선택과 디스패칭 규칙 선택 모두에 필요한 맥락 정보를 포함한다. 즉, 풍부한 상태 표현 자체가 두 의사결정의 품질을 동시에 향상시키는 공통 기반으로 작용한다.
마지막으로 Dual-network 구조의 고유한 기여를 살펴본다. 만약 동일한 상태 정의와 보상 함수를 유지하면서 단일 Qnetwork가 공정대안 선택과 디스패칭 규칙 선택을 결합 행동 공간(Joint Action Space)에서 동시에 학습한다면, 두 가지 구조적 문제가 발생한다. 첫째, 결합 행동 공간의 크기가 L × 6(예: L = 5이면 30개)으로 증가하여 Q-값 추정의 분산이 높아지고, 동일한 에피소드 수 내에서 충분한 탐색이 어려워진다. 둘째, 공정대안 선택은 아직 어떤 설비에도 할당되지 않은 제품을 대상으로 하는 제품 수준의 결정인 반면, 디스패칭 규칙 선택은 설비 유휴 시점에 발생하는 설비 수준의 결정으로, 두 결정에 관련된 상태 정보의 성격이 이질적이다. 단일 네트워크는 이 이질적인 두 결정을 동일한 파라미터로 처리해야 하므로, 각 결정 유형에 특화된 표현을 학습하는 데 한계가 생긴다. Dual-network 구조는 이 두 문제를 각각 독립된 학습 문제로 분해함으로써 해소하며, 이는 보상 함수나 상태 정의만으로는 달성할 수 없는 구조적 이점이다.
종합하면, 보상 함수와 상태 정의는 어떤 네트워크 구조에서도 학습 효율과 방향성을 제공하는 공통 기반이며, Dual-network 구조는 두 의사결정의 이질성으로 인해 단일 네트워크로 처리하기 어려운 MPA 환경의 특수성을 반영한 구조적 기여이다. 세 요소는 서로 대체 관계가 아니라 상호 보완적으로 작용하며, 각 요소의 정량적 기여도를 분리하는 소거 실험은 향후 연구에서 수행할 예정이다.
6. 결론
본 연구에서는 다중공정대안(MPA)을 고려한 제조 스케줄링 문제를 대상으로 Dual-network 기반 심층 강화학습 방법을 제안하였다. 제안된 방법은 두 개의 Q-network를 활용하여 공정 대안 선택과 디스패칭 규칙 선택을 각각 학습하도록 설계하였다. 또한 조립 설비 가동률과 생산 완료율을 보상 함수로 활용하여 생산 단계와 조립 단계 간의 운영 효율을 반영하도록 하였다.
수치 실험 결과, 제안된 방법은 소규모, 중규모, 대규모 인스턴스 전반에서 기존 GA 기반 방법보다 makespan 평균값과 표준편차를 모두 감소시키는 것으로 나타났다. 특히 문제 규모가 증가할수록 성능 개선 효과가 더욱 크게 나타나, 처리시간 변동성이 존재하는 제조 환경에서 제안된 방법이 효과적인 스케줄링 정책을 학습할 수 있음을 확인하였다.
향후 연구에서는 설비 고장이나 신규 작업 유입과 같은 동적 이벤트를 고려한 스케줄링 문제로 확장하고, 실제 제조 시스템 또는 디지털 트윈 기반 환경에서 제안된 방법의 적용 가능성을 검증할 필요가 있다.
FOOTNOTES
-
ACKNOWLEDGEMENT
이 논문은 2025-2026년도 국립창원대학교 자율연구과제와 경남 테크노파크 제조업 AI융합 기반 조성 사업 ‘최적화 시뮬레이션 강화학습 기술을 활용한 자율 생산계획 클라우드 솔루션 개발/구축’ 과제의 연구비 지원으로 수행된 연구결과임.
Fig. 1Positioning of the proposed method relative to prior works
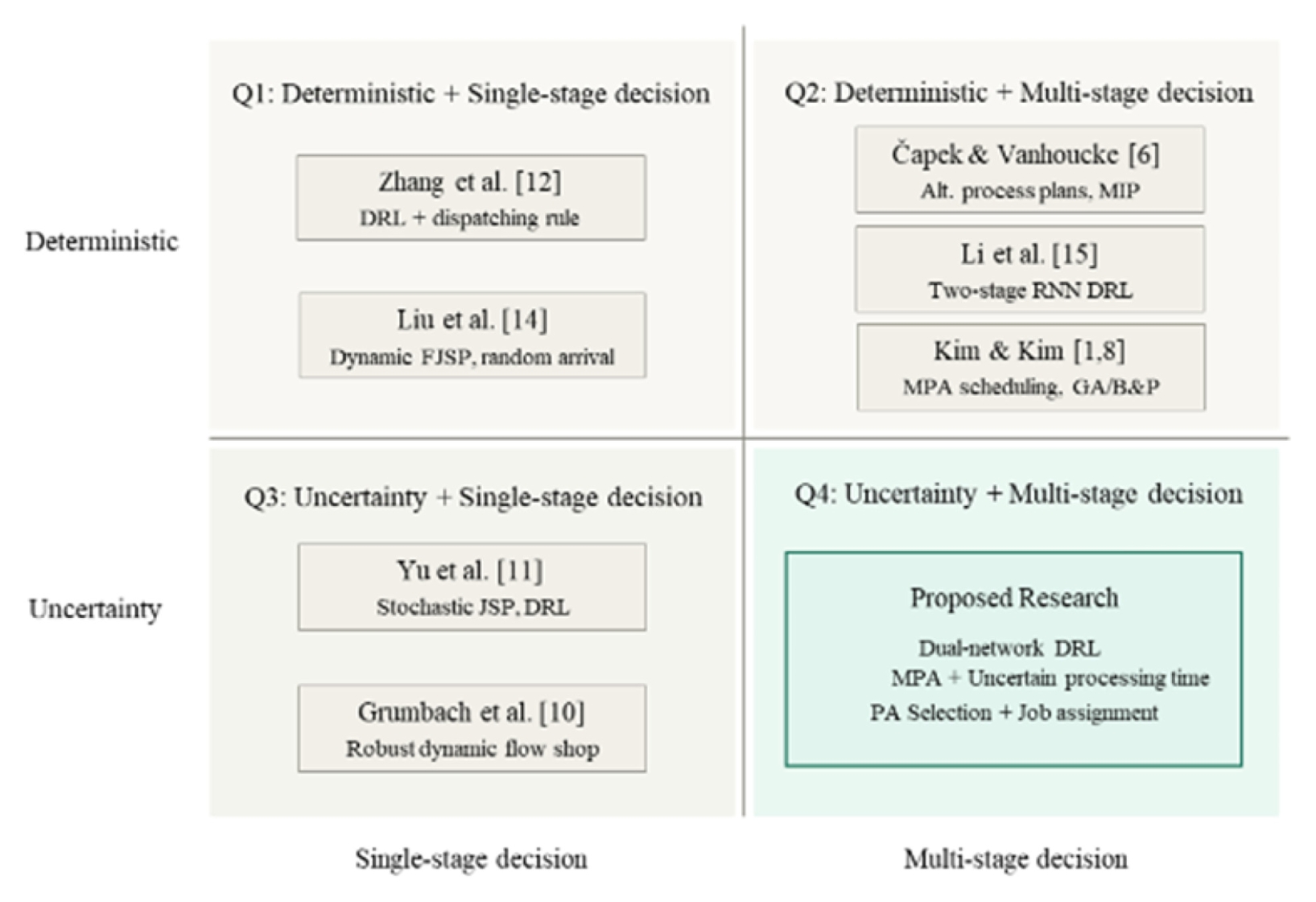
Fig. 2An example of three processing alternatives for producing a product
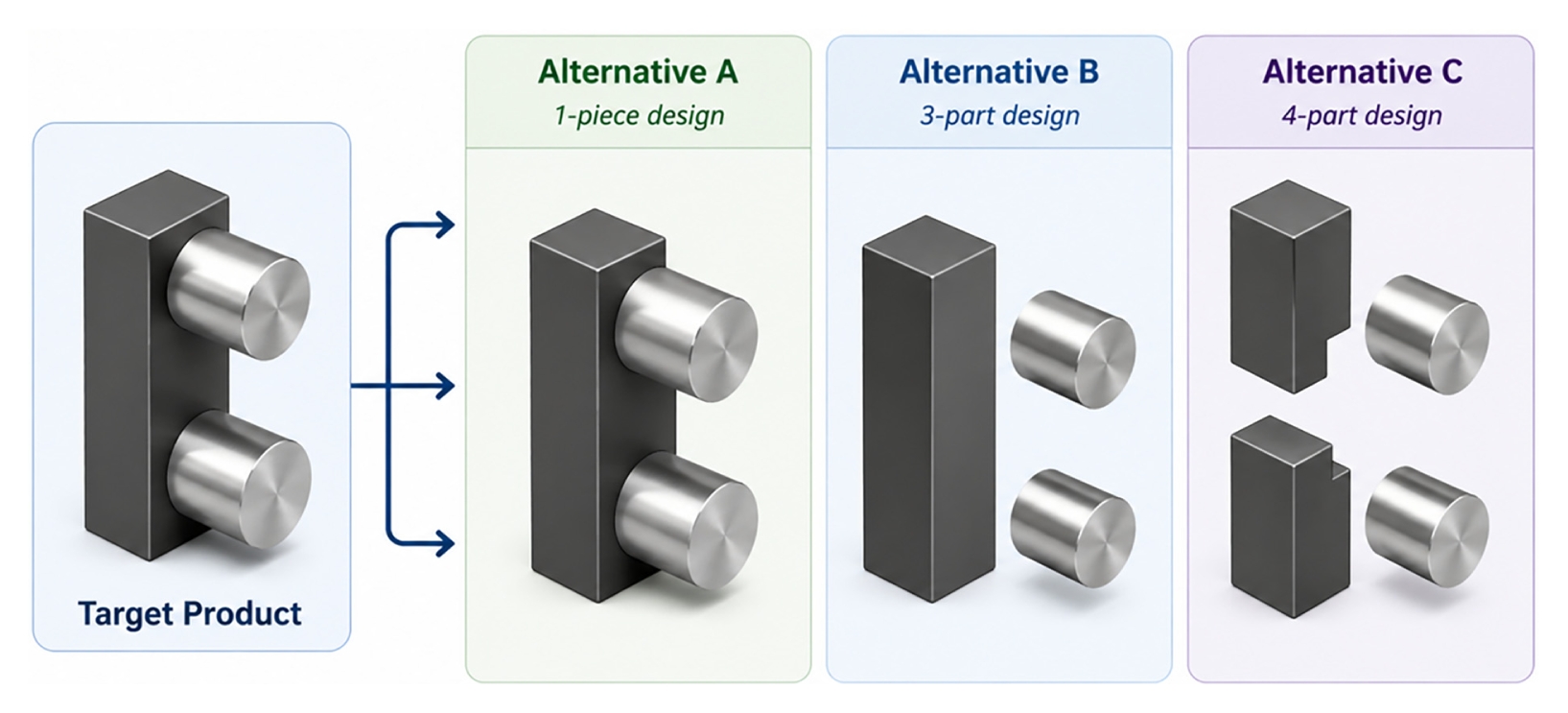
Fig. 3Reinforcement learning architecture
Fig. 4Interaction between agents and environment
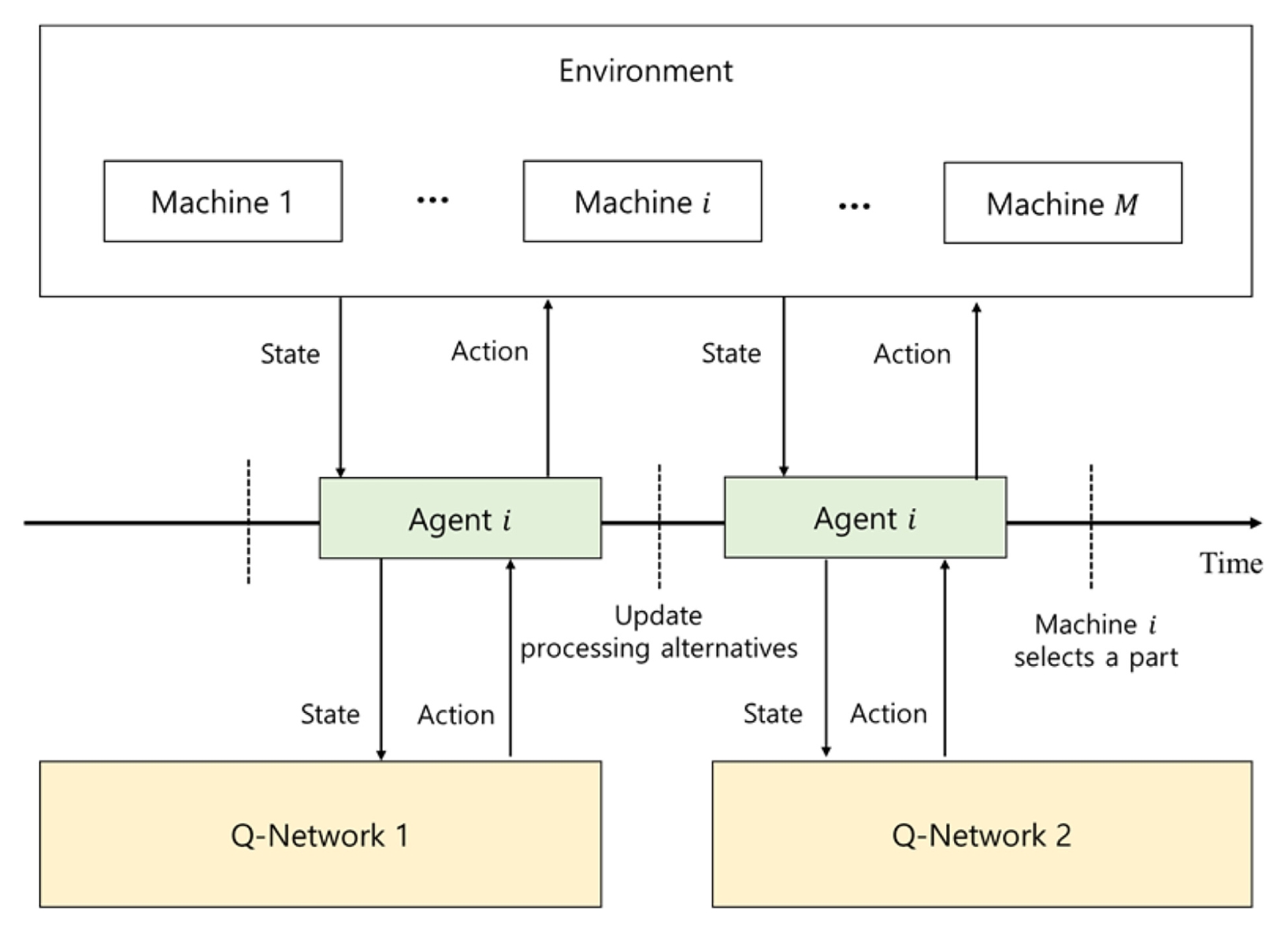
Fig. 5Action for changing the selection of processing alternatives in a way of increasing standard deviation

Fig. 6Action for changing the selection of processing alternatives in a way of decreasing standard deviation

Fig. 7Training algorithm of Q-networks

Table 1
Table 1
|
Category |
State |
|
Statistical values of remaining parts |
Average value of parts’ processing times under the current selection of processing alternatives |
|
Maximum value of parts’ processing times under the current selection of processing alternatives |
|
Minimum value of parts’ processing times under the current selection of processing alternatives |
|
Standard deviation of parts’ processing times under the current selection of processing alternatives |
|
Number of remaining products or pats |
The number of remaining products |
|
The number of processing products |
|
The number of remaining parts |
|
Remaining processing time of each machine |
Remaining processing time of each additive machine |
|
Remaining processing time of each assembly machine |
|
Information of parts and products in buffer |
The number of products in buffer ready to be assembled |
|
The number of products in buffer that needs 1 part to be assembled |
|
The number of products in buffer that needs 2 parts to be assembled |
|
The number of products in buffer that needs 3 parts to be assembled |
|
Maximum assembly time of the product in buffer |
|
Minimum assembly time of the product in buffer |
Table 2Experimental results of small-sized instances (A = 2)
Table 2
|
A = 2 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 2 |
F = 3 |
2.14% |
5.95% |
1.32% |
5.01% |
1.55% |
4.97% |
|
F = 5 |
1.09% |
3.17% |
2.39% |
5.95% |
2.64% |
5.43% |
|
F = 10 |
1.34% |
4.25% |
2.80% |
4.32% |
2.03% |
5.25% |
|
F = 15 |
0.79% |
4.14% |
1.25% |
6.84% |
1.69% |
6.40% |
|
Average |
1.34% |
4.38% |
1.94% |
5.53% |
1.98% |
5.51% |
|
M = 3 |
F = 3 |
1.94% |
5.69% |
3.39% |
4.55% |
2.41% |
4.65% |
|
F = 5 |
2.52% |
4.09% |
1.68% |
4.85% |
1.24% |
3.99% |
|
F = 10 |
1.27% |
5.18% |
2.70% |
3.65% |
2.61% |
3.19% |
|
F = 15 |
1.82% |
6.22% |
2.54% |
5.83% |
2.02% |
5.55% |
|
Average |
1.89% |
5.30% |
2.58% |
4.72% |
2.07% |
4.35% |
Table 3Experimental results of small-sized instances (A = 3)
Table 3
|
A = 3 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 2 |
F = 3 |
1.19% |
3.16% |
2.55% |
4.46% |
0.76% |
3.98% |
|
F = 5 |
1.14% |
3.83% |
1.92% |
3.69% |
1.31% |
4.93% |
|
F = 10 |
0.95% |
4.14% |
1.42% |
3.32% |
2.16% |
2.55% |
|
F = 15 |
0.80% |
2.09% |
0.80% |
2.39% |
0.86% |
4.64% |
|
Average |
1.02% |
3.31% |
1.67% |
3.47% |
1.27% |
4.03% |
|
M = 3 |
F = 3 |
0.91% |
3.90% |
2.26% |
3.70% |
1.81% |
4.78% |
|
F = 5 |
1.23% |
2.51% |
1.57% |
4.23% |
0.79% |
3.74% |
|
F = 10 |
1.09% |
3.72% |
1.68% |
3.44% |
0.86% |
2.32% |
|
F = 15 |
0.96% |
3.11% |
0.93% |
5.21% |
1.85% |
3.70% |
|
Average |
1.05% |
3.31% |
1.61% |
4.15% |
1.33% |
3.64% |
Table 4Experimental results of medium-sized instances (A = 2)
Table 4
|
A = 2 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 5 |
F = 20 |
6.84% |
9.04% |
6.14% |
8.52% |
5.12% |
10.91% |
|
F = 30 |
5.40% |
8.82% |
6.67% |
10.02% |
7.59% |
9.84% |
|
F = 50 |
7.47% |
10.48% |
7.89% |
9.10% |
8.35% |
10.07% |
|
F = 100 |
6.91% |
8.20% |
6.10% |
7.36% |
5.30% |
9.60% |
|
Average |
6.66% |
9.14% |
6.70% |
8.75% |
6.59% |
10.11% |
|
M = 10 |
F = 20 |
6.63% |
8.26% |
6.38% |
8.13% |
5.90% |
8.86% |
|
F = 30 |
8.93% |
9.21% |
7.45% |
9.30% |
6.54% |
10.41% |
|
F = 50 |
5.81% |
8.70% |
6.60% |
9.73% |
5.95% |
10.95% |
|
F = 100 |
6.02% |
10.42% |
5.73% |
8.48% |
7.46% |
9.86% |
|
Average |
6.85% |
9.15% |
6.54% |
8.91% |
6.46% |
10.02% |
Table 5Experimental results of medium-sized instances (A = 3)
Table 5
|
A = 3 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 5 |
F = 20 |
4.38% |
8.14% |
5.50% |
6.12% |
6.57% |
9.24% |
|
F = 30 |
6.68% |
9.67% |
5.17% |
8.59% |
4.84% |
7.58% |
|
F = 50 |
4.53% |
6.89% |
3.44% |
9.35% |
3.85% |
7.97% |
|
F = 100 |
5.16% |
7.10% |
4.62% |
7.30% |
6.14% |
8.23% |
|
Average |
5.19% |
7.95% |
4.68% |
7.84% |
5.35% |
8.26% |
|
M = 10 |
F = 20 |
4.99% |
7.91% |
4.26% |
9.42% |
5.76% |
10.05% |
|
F = 30 |
5.88% |
9.80% |
6.67% |
8.32% |
3.20% |
8.49% |
|
F = 50 |
4.33% |
8.73% |
5.04% |
7.24% |
6.53% |
7.58% |
|
F = 100 |
4.80% |
8.81% |
5.59% |
9.21% |
5.29% |
8.74% |
|
Average |
5.00% |
8.81% |
5.39% |
8.55% |
5.20% |
8.72% |
Table 6Experimental results of large-sized instances (A = 2)
Table 6
|
A = 2 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 15 |
F = 100 |
9.16% |
12.95% |
9.33% |
14.99% |
8.71% |
11.77% |
|
F = 150 |
9.25% |
11.15% |
10.68% |
13.19% |
10.11% |
12.70% |
|
F = 200 |
8.47% |
14.89% |
9.54% |
15.59% |
10.67% |
14.91% |
|
Average |
8.96% |
13.00% |
9.85% |
14.59% |
9.83% |
13.13% |
|
M = 20 |
F = 100 |
9.31% |
11.89% |
9.34% |
11.38% |
10.17% |
11.66% |
|
F = 150 |
10.85% |
10.31% |
9.79% |
12.23% |
9.31% |
12.39% |
|
F = 200 |
10.68% |
16.42% |
10.42% |
13.46% |
9.90% |
13.71% |
|
Average |
10.28% |
12.87% |
9.85% |
12.36% |
9.79% |
12.59% |
Table 7Experimental results of large-sized instances (A = 3)
Table 7
|
A = 3 |
L = 2 |
L = 3 |
L = 5 |
|
Average reduction |
Std reduction |
Average reduction |
Std reduction |
Average reduction |
Std reduction |
|
M = 15 |
F = 100 |
8.241 |
1.24 |
8.86 |
12.12 |
9.55 |
8.88 |
|
F = 150 |
8.68 |
11.22 |
9.91 |
11.86 |
8.61 |
12.81 |
|
F = 200 |
9.12 |
10.64 |
8.65 |
11.04 |
10.30 |
11.83 |
|
Average |
8.68 |
11.03 |
9.141 |
1.67 |
9.49 |
11.17 |
|
M = 20 |
F = 100 |
8.33 |
10.45 |
9.28 |
9.02 |
10.57 |
10.73 |
|
F = 150 |
9.70 |
9.54 |
8.67 |
10.83 |
9.81 |
11.05 |
|
F = 200 |
8.05 |
11.06 |
7.57 |
10.42 |
7.42 |
10.21 |
|
Average |
8.69 |
10.35 |
8.51 |
10.09 |
9.27 |
10.66 |
REFERENCES
- 1. Kim, J., Kim, H.-J., (2021), Parallel machine scheduling with multiple processing alternatives and sequence-dependent setup times, International Journal of Production Research, 59(18), 5438-5453.
- 2. Holland, J. H., (1992), Genetic algorithms, Scientific American, 267(1), 66-72.
- 3. Kirkpatrick, S., Gelatt, C. D., Vecchi, M. P., (1983), Optimization by simulated annealing, Science, 220(4598), 671-680.
- 4. Chang, J., Yu, D., Hu, Y., He, W., Yu, H., (2022), Deep reinforcement learning for dynamic flexible job shop scheduling with random job arrival, Processes, 10(4), 760.
- 5. Liu, R., Piplani, R., Toro, C., (2022), Deep reinforcement learning for dynamic scheduling of a flexible job shop, International Journal of Production Research, 60(13), 4049-4069.
- 6. Čapek, R., Šůcha, P., Hanzálek, Z., (2012), Production scheduling with alternative process plans, European Journal of Operational Research, 217(2), 300-311.
- 7. Moon, C., Kim, J., Hur, S., (2002), Integrated process planning and scheduling with minimizing total tardiness in multi-plants supply chain, Computers & Industrial Engineering, 43(1–2), 331-349.
- 8. Kim, J., Kim, H.-J., (2022), An exact algorithm for an identical parallel additive machine scheduling problem with multiple processing alternatives, International Journal of Production Research, 60(13), 4070-4089.
- 9. Zhang, L., Feng, Y., Xiao, Q., Xu, Y., Li, D., Yang, D., Yang, Z., (2023), Deep reinforcement learning for dynamic flexible job shop scheduling problem considering variable processing times, Journal of Manufacturing systems, 71, 257-273.
- 10. Grumbach, F., Müller, A., Reusch, P., Trojahn, S., (2024), Robust-stable scheduling in dynamic flow shops based on deep reinforcement learning, Journal of Intelligent Manufacturing, 35(2), 667-686.
- 11. Wu, X., Yan, X., Guan, D., Wei, M., (2024), A deep reinforcement learning model for dynamic job-shop scheduling problem with uncertain processing time, Engineering Applications of Artificial Intelligence, 131, 107790.
- 12. Zhang, C., Song, W., Cao, Z., Zhang, J., Tan, P. S., Chi, X., (2020), Learning to dispatch for job shop scheduling via deep reinforcement learning, Advances in Neural Information Processing Systems, 33, 1621-1632.
- 13. Wan, L., Cui, X., Zhao, H., Li, C., Wang, Z., (2024), An effective deep actor-critic reinforcement learning method for solving the flexible job shop scheduling problem, Neural Computing and Applications, 36(20), 11877-11899.
- 14. Zhao, L., Fan, J., Zhang, C., Shen, W., Zhuang, J., (2023), A drl-based reactive scheduling policy for flexible job shops with random job arrivals, IEEE Transactions on Automation Science and Engineering, 21(3), 2912-2923.
- 15. Li, F., Lang, S., Hong, B., Reggelin, T., (2024), A two-stage rnn-based deep reinforcement learning approach for solving the parallel machine scheduling problem with due dates and family setups, Journal of Intelligent Manufacturing, 35(3), 1107-1140.
- 16. Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., (2015), Human-level control through deep reinforcement learning, Nature, 518(7540), 529-533.
- 17. Park, I.-B., Huh, J., Kim, J., Park, J., (2019), A reinforcement learning approach to robust scheduling of semiconductor manufacturing facilities, IEEE Transactions on Automation Science and Engineering, 17(3), 1420-1431.
Biography
- Jun Kim
Assistant Professor in the Department of Industrial and Systems Engineering, Changwon National University. His research interest is smart manufacturing.